Torna alla pagina di Elementi di sicurezza e privatezza
:: Affidabilità del software ::
Virus
Concetti generali
Il virus è un software in grado di infettare altri programmi modificandoli in modo che ne contengano una copia al loro interno; ogni programma infetto agisce a sua volta come un virus. E' dunque composto da due parti, una che svolge le funzioni di duplicazione e l'altra quelle di danneggiamento (inteso come violazione della sicurezza, non necessariamente grave).
A seconda delle caratteristiche di attivazione, i virus si possono classificare in:
- transienti, quando la vita del virus dipende da quella del programma che lo ospita. In altre parole il virus è in esecuzione se e solo sé è in esecuzione il programma infetto
- residenti, quando il virus è in memoria e rimane attivo o può essere attivato come un programma stand-alone, quindi indipendente dal programma infetto.
Un virus racchiude in sé le caratteristiche di alcuni tipi di malware, in particolare:
- dei cavalli di troia condivide il fatto che entrambi inseriscono nei codici dei programmi infetti funzionalità non note. Notare che non è sempre vero che un trojan è anche un virus, dipende se si duplica o no
- come le bombe logiche può attivarsi al verificarsi di certi eventi o condizioni
- può permettere accessi non autorizzati al sistema proprio come le trapdoor
- con i worm ha in comune la proprietà di propagarsi all'interno del sistema centralizzato (quindi non necessariamente attraverso la rete)
- dei rabbit può condividere la finalità di replicare sé stesso per saturare le risorse del sistema
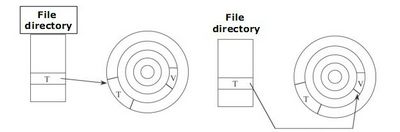
Il codice malizioso dei virus viene attivato solo una volta mandato in esecuzione, dopodiché infettano attaccandosi o sostituendosi ad una porzione di codice. In base alle strategie di infezione distinguiamo virus che attaccano il programma esternamente (non sovrapposto), che lasciano il programma utilizzabile ma intanto gli aggiungono istruzioni dannose (quindi il programma infetto avrà una dimensione maggiore rispetto a prima), e virus che attaccano internamente (sovrapposto) che effettuano un replacement delle istruzioni del programma, rendendolo di fatto inutilizzabile. Nelle due figure successive viene rappresentata visivamente questa distinzione, illustrando la situazione prima dell'infezione (a sinistra) e dopo (a destra); in particolare, T rappresenta il programma originale, mentre la porzione V è quella infetta.
Infezione sovrapposta

Infezione non sovrapposta
Perché un codice malizioso possa essere considerato virus, oltre alle caratteristiche viste finora deve inoltre:
- essere difficile da individuare dagli antivirus
- essere difficile da cancellare o deattivare, perché se lo costruisci non vuoi che sia reso facilmente inoffensivo
- diffondersi rapidamente, cercando di infettare il maggior numero di sistemi informatici nel minor tempo possibile
- infettare non solo il programma che lo ospita
- essere facile da creare
- essere indipendente dal sistema operativo, anche se la maggior parte è dedicata ad uno ben preciso che inizia per W e finisce per indows
Esiste inoltre un tipo particolare di virus che attacca il boot sector, quindi infetta il sistema prima che qualsiasi antivirus possa entrare in esecuzione. La normale procedura di bootstrap prevede: accensione del computer e test dei componenti hardware, lettura del boot sector da hard disk, caricamento del bootstrap loader che carica il sistema operativo. In seguito all'infezione dei virus in questione si avrebbe invece: accensione del computer e test dei componenti hardware, esecuzione del virus, caricamento del boostrap loader che carica il sistema operativo col virus già in esecuzione.
Tecniche di rilevamento
La maggior parte dei virus può essere identificata con una specifica stringa di bit, detta firma del virus o signature. La firma caratterizza i virus e può essere sfruttata dai software antivirus per la loro rilevazione, ma con riserva, dato che certe sequenze di bit potrebberero dare adito a falsi positivi.
Ci sono diversi modi per riconoscere un virus, attraverso i pattern di memorizzazione, i pattern di esecuzione e i pattern di trasmissione. Vediamoli singolarmente.
I pattern di memorizzazione tengono in considerazione il fatto che il codice del virus può iniziare con una sequenza di byte invariante, che può rivelarsi una signature rintracciabile. Da notare che all'interno del programma infetto la porzione di codice contenente il virus non si trova necessariamente all'inizio, ma anche in fondo o dopo tot byte, comunque nella stessa posizione. Un altro pattern di memorizzazione sospetto potrebbe essere un programma il cui codice comincia con un'istruzione di jump, saltando subito altrove prima ancora di definire le variabili. I pattern di memorizzazione sono la tecnica di rilevazione più semplice da realizzare ed una delle più affidabili.
Considerare i pattern di esecuzione significa osservare il comportamento del virus una volta eseguito, in particolar modo le modalità di diffusione, le tecniche adottate per non essere individuato, l'entità e la tipologia dei danni provocati. Una tecnica di riconoscimento di questo tipo non è comunque banale, dal momento che modifiche al file directory potrebbero essere effettuate da processi non infetti in modo del tutto legittimo.
Infine, l'individuazione di un pattern di trasmissione si basa sul presupposto che un virus adotti sempre la stessa metodologia di diffusione, quindi è la diffusione stessa una signature. Piuttosto inefficace come strategia, dato che difficilmente un virus avrà un unico pattern di trasmissione.
Gli antivirus si concentrano prevalentemente sui pattern di memorizzazione, ma dato che uno dei principali obiettivi dei programmatori di virus è non far scoprire le loro creature, esistono dei sistemi per mascherarne le signature. Una tecnica piuttosto diffusa è rendere dinamica la firma, continuando a cambiarla ad ogni infezione scegliendo tra un range limitato di stringhe alternative. L'evoluzione successiva è il virus polimorfo, che può assumere un numero elevato o illimitato di forme diverse. Non è sufficiente che utilizzi stringhe casuali se poi le inserisce sempre nella stessa posizione, o si potrebbe considerare come signature le parti che rimangono invariate; un virus polimorfo come si deve invece deve cambiare, suddividere e distribuire il proprio codice in varie porzioni del programma da infettare.
Un ulteriore raffinamento per rendere il rilevamento ancora più difficoltoso è fare sì che il virus polimorfo adoperi tecniche crittografiche per cambiare forma. Il virus crittografico è più complesso da realizzare, ed è composto da tre parti:
- una chiave di decrittazione che varia da infezione a infezione
- il codice crittato, ovviamente
- una routine in chiaro per la decrittazione del codice, che potrebbe essere sfruttata come signature del virus
Ultima considerazione da fare sui virus è che il loro codice sorgente è tipicamente di piccole dimensioni, in modo da nascondersi facilmente in programmi più grossi. Confrontare infatti due istanze dello stesso programma una infetta e l'altra no, darebbe quasi sicuramente lo stesso risultato di un confronto tra due istanze "pulite". La procedura che determina se due programmi sono equivalenti rappresenta infatti un problema non decidibile dato che diversità nelle dimensioni potrebbero essere indotte da cause interne, quindi non legate all'azione dei virus.
Trapdoor
Una trapdoor è un punto di ingresso non documentato ad un modulo o a un programma che un utente maligno potrebbe sfruttare per accedere al sistema (se fosse documentato probabilmente sarebbe anche protetto). La loro creazione avviene generalmente in buona fede, dal momento che vengono spesso inserite in fase di sviluppo del codice per testare il programma, o tenuti in seguito per manutenerlo; vanno però tolti una volta rilasciato il software, perché lasciano pericolosi buchi nella sicurezza.
Un particolare tipo di trapdoor è quello legato a un controllo approssimativo degli errori all'interno di un programma, in particolare in riferimento ai dati in ingresso. Se non viene verificata l'ammissibilità dei dati in input, un utente malizioso potrebbe infatti causare effetti indesiderati nel sistema. E' ciò che accade con le SQL injection, dove l'attaccante sfrutta un punto di ingresso (ad esempio una form) per fornire una stringa SQL in grado di provocare danni al database (ad esempio una drop table). Controllare sempre che l'input sia quello che ci si aspetta è quindi un'ottima regola da applicare per garantire maggiore sicurezza (vedi più avanti per maggiori dettagli)
Salami attack
Con il termine salami attack non ci si riferisce a un sistema ben preciso, ma è piuttosto la generalizzazione di una strategia per compiere illeciti. L'osservazione che sta alla base di questa tecnica è che i piccoli crimini informatici hanno maggior probabilità di sfuggire ai controlli rispetto a quelli più eclatanti; dunque si avvia una catena di piccoli attacchi che singolarmente passano inosservati, ma nel complesso provocano danni significativi.
L'esempio classico è quello del programma che gestisce le transazioni all'interno di una banca, e che per forza di cose avrà spesso a che fare con delle approssimazioni. Un programmatore malintenzionato potrebbe fare in modo di trasferire tali scarti monetari su un altro conto: si tratta di millesimi, ma dai e dai diventano una fortuna.
La stessa tecnica si può applicare a diversi contesti, non solo a quello monetario. Ad esempio con procedimenti analoghi si possono intercettare delle informazioni.
Attacchi su canali di comunicazione
Le comunicazioni hanno normalmente luogo attraverso canali legittimi stabiliti dal sistema per far colloquiare le parti in gioco. A questi canali se ne possono aggiungere altri non convenzionali, detti covert channel (canale coperto), in grado di operare secondo protocolli di comunicazione inusuali e insospettati. Possono essere utilizzati per trasferire informazioni che violano le politiche di sicurezza, ma anche per sfuggire alle analisi del traffico web, come accade con il software Tor.
Un tipo di canale coperto che sfrutta la presenza o l'assenza di oggetti in memoria per sottrarre informazione è lo storage channel. Alcuni esempi:
- il canale file lock segnala in un bit di informazione se in un sistema multiutente un file è bloccato (quindi usato), oppure no
- con la quota disco avviene invece un tentativo da parte del programma spia di creare un file di grosse dimensioni. Se ci riesce significa che c'è ancora spazio disponibile sul disco, altrimenti significa che è occupato da qualcos'altro
- uno storage channel che verifica l'esistenza di un file, semplicemente cercando di aprirlo
Qualsiasi tecnica decidessimo di utilizzare, è comunque sottointeso che il programma spia dovrà avere accesso alle risorse condivise del sistema, e se in particolare vorrà intercettare le comunicazioni di un programma di servizio, dovrà condividere con lui anche la nozione di tempo.
Vediamo infine il timing channel, più subdolo e complesso, che spia se i programmi di servizio usano o meno il tempo di computazione ad essi assegnato dal sistema operativo, ottenendo sempre 1 bit di informazione per rilevazione (se il tempo di computazione assegnato viene usato allora si segnala 1; s il tempo non viene usato si segnala 0). Basta pensare alla quantità di processi normalmente attivi in un ambiente multitasking per rendersi conto dell'estrema complessità di questa strategia.
Identificare i covert channel
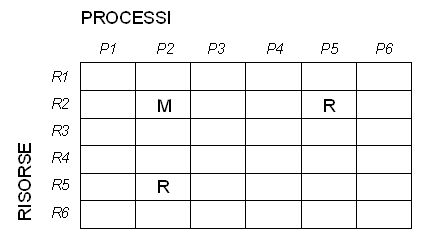
Individuare i covert channel è un'operazione per niente banale, dato che essi sfruttano sistemi ordinari (standard) per ottenere le informazioni da dare in pasto ai programmi spia. Una tecnica consiste nell'analizzare come vengono utilizzate le risorse condivise dai vari processi in esecuzione nel sistema, dato che sono le uniche su cui può interferire un covert channel. Si costruisce una matrice (ideata da Kemmerer) in cui le righe sono le risorse e le colonne i processi; per ogni cella si scrive poi R se il processo j può leggere o osservare la risorsa i, o M se invece può accedervi in scrittura. Le condizioni perché ci sia un covert channel sono:
- due o più processi devono avere accesso ad una risorsa in comune
- almeno uno dei processi coinvolti deve essere abilitato per l'accesso in scrittura su tale risorsa
- la scrittura sulla risorsa utilizza informazioni prelevate da altre risorse cui il processo ha legittimo accesso
Un esempio in figura:
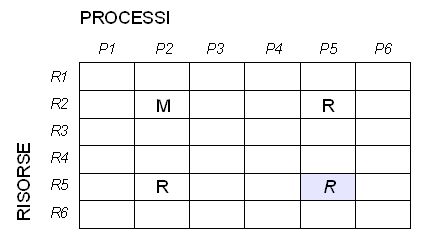
Questa situazione è sospetta, in quanto se la modifica di R2 da parte di P2 è legata alla lettura della risorsa R5, il processo P5 accede ad essa indirettamente. Potremmo cioè avere la seguente situazione:
Abbiamo parlato di sospetti, perché di questi si tratta: una volta individuati i flussi potenziali di informazione, essi vanno studiati. Possiamo così avere quattro scenari:
- tali flussi sono legali
- tali flussi non comportano il passaggio di informazioni di interesse tra i processi
- i processi mittente e ricevente sono lo stesso
- abbiamo rilevato un covert channel!
Denning ha ideato un altro sistema per identificare i covert channel, l' analisi del flusso di informazione, che analizza direttamente le istruzioni di un programma. Studiando il codice sorgente dei programmi si possono infatti scoprire flussi di informazione non ovvi tra le varie istruzioni. Un esempio di flusso esplicito è un normale assegnamento, ad esempio in B := A le informazioni vanno da A a B. Un flusso implicito è invece quello che va da D a B nell'istruzione: if (D == 1) then B := A , se B effettua l'assegnamento è perché sa che D è pari a 1. Un ultimo esempio di flusso implicito è quello delle chiamate di funzione, che generalmente assegnano sempre valori di ritorno. C'è da ricordare però che i flussi impliciti non sono necessariamente legati a tentativi di violazione, ma bisogna comunque porvi le dovute attenzioni.
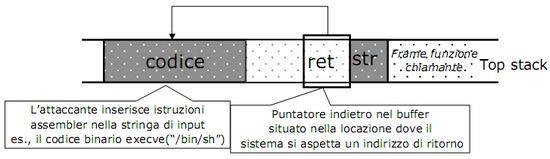
Buffer overflow
I bug sono errori nel codice del software che possono essere sfruttati per violare la sicurezza del sistema. Per quanto un programmatore possa prestare attenzione al proprio lavoro, i bug sono praticamente inevitabili; cionondimeno (!!!) ne esistono alcuni tipici abbondantemente documentati e decisamente da evitare. Uno di questi è il buffer overflow (BOF).
Il buffer è una porzione di memoria (stack e heap) usata per memorizzare temporaneamente i dati utilizzati dai vari programmi, ha una dimensione ben precisa e generalmente non effettua alcun controllo su ciò che contiene. Per overflow del buffer si intende inserirvi più dati di quanti ne possa in realtà contenere, il che comporta una sovrascrittura delle zone di memoria adiacenti e dunque potenziali vulnerabilità. Programmatori maliziosi potrebbero infatti sfruttare il BOF per sovrascrivere codice eseguibile nello stack per prendere possesso del sistema, o comunque "scombinare" i dati nel buffer in modo tale che il programma non funzioni più correttamente. I buffer overflow avvengono generalmente nel contesto di chiamate di funzione, di cui vengono alterati i valori degli indirizzi di ritorno e dell'istruzione successiva inficiando la normale esecuzione.
Vediamo ora un esempio.
Abbiamo la seguente porzione di codice, che copia all'interno di un array di dimensione 126 il contenuto di un altro array passato come parametro:
void func(char *str)
{
char buf[126];
strcpy(buf, str);
}
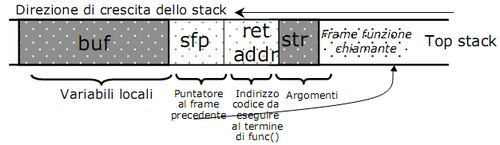
La chiamata di questa funzione provoca l'inserimento di un nuovo frame nello stack, dove per frame si intende una sequenza di dati.
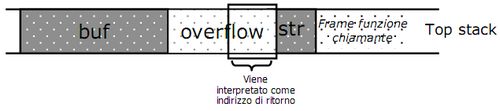
L'area di memoria puntata da str è inserita nello stack, ma se la sua lunghezza è superiore a 126 byte allora la stringa andrà a sovrascrivere le celle adiacenti. Nella figura sotto vediamo che andrà a sovrapporsi all'area contenente l'indirizzo di ritorno.
Se la stringa data in pasto al programma era stata creata ad hoc per violare la sicurezza attraverso un attacco di tipo buffer overflow, l'area appena sovrascritta potrebbe contenere un nuovo puntatore che indirizza a una porzione di codice malizioso.
Dall'esempio possiamo trarre alcune conclusioni aggiuntive rispetto alle considerazioni precedenti:
- l'attaccante deve indovinare o conoscere esattamente la posizione nello stack in cui si troverà il buffer quando verrà chiamata la funzione, o il suo tentativo non porterà ai risultati (da lui) sperati
- in questo caso è stata sfruttata una vulnerabilità della funzione
strcopy(), che fa parte della libreria string.h del linguaggio C. Esempi di altre funzioni insicure sono strcat(), gets(), scanf(), printf()
- la vulnerabilità delle funzioni dipende dal linguaggio di programmazione utilizzato
- notare come un overflow di 1 byte non avrebbe cambiato l'indirizzo di ritorno, ma il puntatore al frame precedente (overflow off-by-one)
Evitare il BOF non è un compito particolarmente ingrato, sono sufficienti alcuni accorgimenti
- prima di tutto bisogna implementare delle routine di controllo della correttezza dei dati in input, facendo in modo tra le altre cose che l'utente non possa inserirne più del dovuto
- randomizzare la posizione dello stack o crittare l'indirizzo di ritorno potrebbe essere una buona idea, dato che non permetterebbe all'attaccante di conoscere quale indirizzo di ritorno usare nella sua stringa maliziosa.
- altro accorgimento è rendere lo spazio dello stack non eseguibile, impostando opportunamente il bit NX (no execute) per tale area di memoria.
- una soluzione alternativa e definitiva è usare linguaggi di programmazione sicuri, ad esempio Java, che rilevano le condizioni anomale e interrompono l'esecuzione del programma.
Torna alla pagina di Elementi di sicurezza e privatezza