Torna alla pagina di Ingegneria del Software
:: Ingegneria del Software - Appunti del 16 Marzo 2009 ::
Sintassi e semantica
I casi d'uso, visti nelle lezioni precedenti, sono dotati di sintassi ma non di semantica. Dobbiamo vedere bene che cosa significhi questa affermazione, perché si rivelerà di capitale importanza.
Un linguaggio ha una sintassi quando posso dire, in base a regole certe, se una certa sua istanza è ben formata o no, ovvero se sto rispettando le regole relative all'ordine con cui i simboli dell'alfabeto del linguaggio vanno messi.
Sotto questo punto di vista, i CdU hanno una sintassi: infatti, guardando un diagramma posso dire se è un CdU o no analizzandolo. Per fare un esempio, se vedo due ellissi senza nessuna freccia in mezzo, posso dire senza tema di smentita che quel diagramma non è ben formato.
Attenzione: nel caso dei CdU, il linguaggio è composto da diagrammi e non solo da parole, ma ai fini della definizione questo non è importante. Ciò che conta è che ci sia un insieme di simboli ben definito, e delle regole per combinarli.
Un linguaggio ha una semantica quando posso prendere un'istanza del linguaggio stesso e riferirlo, in modo matematico, ad un dominio.
Per capire bene che cosa significhi, prendiamo i nostri CdU. Quando una persona guarda il diagramma di un CdU possono venirgli in mente diverse cose: a me viene in mente questo, a te viene in mente quello. Chi ha ragione? Sicuramente avrà ragione il cliente, ma il problema è che solo guardando il diagramma non posso capire con esattezza che cosa intendeva chi l'ha disegnato.
Questo avviene perché i CdU non sono dotati di una semantica vera e propria, ovvero, non è possibile guardare un diagramma e, con una funzione matematica, darne un'interpretazione univoca e non ambigua. Come appena mostrato, l'interpretazione non è affatto univoca, proprio perché io lo interpreto in un modo e tu in un altro.
Certo, i CdU non sono messi proprio così male. In fondo, le interpretazioni che si danno di un CdU si somigliano tutte (pur non essendo uguali), e per questo motivo diciamo che i CdU hanno una semantica informale, la quale può essere vista come una via di mezzo tra un'interpretazione univoca per tutti, e l'anarchia.
Il vantaggio dei CdU è che sono facilmente comprensibili, cioè "danno l'idea" del sistema anche alle persone che non sanno niente di matematica, o ai tanto vituperati manager; un computer però avrebbe dei problemi ad interpretare un CdU, proprio per l'assenza di semantica.
Al contrario, un linguaggio dotato di una semantica formale sarà sicuramente comprensibile in modo algoritmico da un calcolatore, ma probabilmente un essere umano o un manager che lo guardano avranno difficoltà a comprenderlo.
Sopra abbiamo detto che la semantica permette un'associazione matematica da un insieme di simboli ben formati ad un certo dominio, in modo univoco.
Ci sono due modi per realizzare questa associazione matematica: la funzione e l'applicazione. Vediamo di chiarire bene la differenza tra questi due termini.
Una funzione è una roba scritta in genere così: f: X -> Y dove
- X è il dominio, ovvero l'insieme degli elementi dati in pasto alla f
- Y è il codominio, ovvero l'insieme degli elementi che la f sputa fuori
- f è una legge che ad ogni elemento di X associa uno e uno solo elemento di Y
Un'applicazione dovrebbe essere sinonimo di funzione, però viene anche usata per distinguere tra le funzioni definite come qui sopra, e quelle altre funzioni meno "potenti" che invece non associano ad ogni elemento di X un elemento di Y.
Questa definizione va chiarita...
DFD
DFD = Data Flow Diagram. Si tratta di un linguaggio informale, non dotato di semantica, spesso usato per specificare strutture aziendali, ma che si presta anche alla specifica dei requisiti.
Similmente ai casi d'uso, è composto da ellissi e frecce, ma prevede anche delle righe nere più spesse che possono essere sorgenti o pozzi di informazione.
- ellissi = attività, proprio come nei Cdu
- frecce = flussi di informazione tra le varie attività
- righe = sorgenti di informazione oppure pozzi di informazione'' oppure un misto tra i due, ovvero punti in cui l'informazione entra oppure esce dal sistema.
I DFD, come dice il loro nome, visualizzano quindi in modo immediato il "giro" che l'informazione fa dentro un sistema, e niente altro. Ciò significa che non ci sono né strutture per il controllo né indicazioni di temporizzazione ("quando devo attivare un processo?"), ma solo flussi di informazione.
A causa di ciò, un DFD deve presentare tutti i possibili flussi di informazione che un sistema prevede, ovvero tutte le possibili strade alternative che l'informazione può prendere. Devono inoltre realizzare un dizionario univoco con i nomi e le definizioni, e nel caso delle frecce anche le informazioni che trasporta.
Ma, mancando le strutture di controllo, mancano totalmente anche i modi per segnalare quando intraprendere una strada e quando un'altra. Il fatto che una freccia entri in un'ellisse non vuol dire che, non appena arriva l'informazione, si esegue l'attività di quell'ellisse, perché non sta scritto da nessuna parte. Così come i CdU, quindi, i DFD non tengono in nessuna considerazione i fattori legati al tempo.
Questa mancanza di "attenzione" al tempo si spiega con il fatto che i DFD sono privi di semantica. I requisiti di temporizzazione e di sincronizzazione vanno specificati ben bene in modo da non lasciare nessun dubbio in chi li legge. L'unico modo per non lasciare dubbi in chi legge un diagramma è avere una semantica. I DFD, visto che li usano i manager, non hanno semantica, e quindi evitano il problema delle ambiguità legate al tempo ignorandole del tutto.
Alberi decisionali
Così come il solo diagramma di un CdU non era completo, ma andava corredato di un bello schemino per capire le precondizioni, le postcondizioni e varie note, così anche i DFD vanno completati con un albero decisionale, il quale supplisce all'impossibilità di rappresentare delle condizioni in un diagramma.
Per ciascuna ellisse del mio DFD occorre un albero decisionale, così capisco le condizioni di quell'attività. Volendo posso poi accorparle tutte in un unico mega-albero, sicuramente completo ma a prezzo di minor comprensibilità e immediatezza.
DFD + alberi decisionali raggiungono un considerevole potere espressivo per gli utenti, sicuramente più dei CdU che devono mettere giù le precondizioni per iscritto (a meno che - e nessuno ce lo vieta - corrediamo anche il caso d'uso di un albero decisionale).
Ambiguità dei DFD
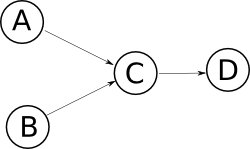
I DFD sono potenzialmente ambigui. Perché mancano di semantica? Certo, ma vediamo un esempio.
Questo è un DFD. L'ambiguità sta proprio nelle frecce del DFD, che non ci aiutano a capire una cosa: quando vado da C a D? Possibili risposte sono:
- quando arriva A
- quando arriva B
- quando sono arrivati entrambi
- prima deve arrivare A, poi B
- prima deve arrivare B, poi A
Ecco qui l'ambiguità: io lo guardo e capisco una cosa. Tu lo guardi e ne capisci un'altra, e ovviamente il cliente ne intendeva una terza.
Domanda da esame: "perché questo DFD è ambiguo?"
Il problema della sincronizzazione
Abbiamo già intuito che il problema della sincronizzazione è un problema grosso. Le modalità e i tempi di comunicazioni tra le varie attività, in certi casi, sono importantissimi, e sia i CdU che i DFD non permettono di esprimere questo tipo di relazione.
Nel caso in cui A produca e B consumi, i casi classici della sincronizzazione sono i seguenti:
- tipo unbuffered: A può produrre solo dopo che B ha consumato il dato precedente
- tipo buffered: A produce finché c'è spazio nel buffer (ovvero nel canale di comunicazione); B mangia fintantoché il buffer non è vuoto.
Tutto ciò ci fa capire che per alcuni requisiti è necessaria un'espressione più formale, in particolare proprio per quelli che riguardano la sincronizzazione. Che tecniche posso usare?
- un'estensione dei DFD, che vedremo fra poco
- modelli operazionali come gli automi a stati finiti o le reti di Petri, che vedremo poi
Estensione dei DFD: i FDFD
I DFD possono essere estesi per venire incontro ai problemi della sincronizzazione. In questo caso vengono chiamati FDFD, ovvero Formal DFD.
Le nostre ellissi, nei FDFD, diventano trasformatori di dati: hanno m ingressi, cioè le frecce entranti, e hanno n uscite, ovvero le frecce uscenti. In questo modo posso rappresentare le ellissi come funzioni matematiche parziali, dove parziali significa che non tutto il codominio è mappato dalla funzione.
Per avere una vera semantica occorre che da qualche parte io scriva: "questa ellisse, pardon, questo trasformatore di dati prende in ingresso due numeri interi e ne restituisce la moltiplicazione". In questo modo c'è un'interpretazione univoca della funzione dell'ellisse, e sono felice.
Mancano ancora, tuttavia, le strutture di controllo: questo trasformatore, quando viene attivato?
I contenitori di dati
I contenitori di dati sono rappresentati da dei quadrati, in cui il numero interno rappresenta la loro capacità, cioè il numero di dati che possono contenere. I contenitori sono dunque nuovi elementi lessicali che indicano quando saranno utilizzabili gli input, operando così una funzione di controllo: le attività saranno abilitate solo se i loro contenitori avranno un certo valore.
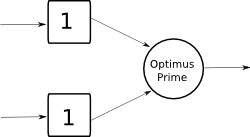
TransformerIl transformer Optimus Prime sarà eseguito solo se i due contenitori alla sua sinistra avranno riempito la loro capacità. La freccia indica che il dato prodotto dal quadrato sarà consumato dal transformer, e pertanto ogni volta che vengono consumati i dati, ne occorrono di nuovi per attivare di nuovo Optimus Prime.
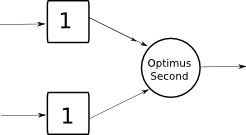
Un'altro transformerQuesto transformer è diverso perché dal primo contenitore parte una freccia con 2 punte. Ciò sta a significare che la lettura non è distruttiva: il dato che il quadrato produce non viene distrutto da Optimus Second, ma rimane lì, e quindi Optimus Second funzionerà ogni qual volta il secondo quadrato produrrà un dato. In pratica, è come se stessimo sincronizzando Optimus col secondo contenitore di dati: attendo solo lui, e non più il primo quadrato. È più facile da intuire che da spiegare:)
Automi
Per quanto riguarda gli automi, inviterei ad andare alla pagina di Linguaggi di Programmazione per la Sicurezza che tratta proprio questo argomento. Quello che interessa a noi va dall'inizio fino al paragrafo "Limiti delle FSM".
Torna alla pagina di Ingegneria del Software