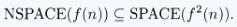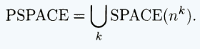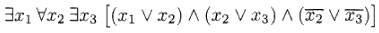Torna alla pagina di Informatica Teorica
:: Informatica Teorica - Spazio-complessità ::
Appunti & Dimostrazioni del 19 Maggio
Complessità in termini di spazio
Così come è possibile quantificare la complessità di un algoritmo in funzione della risorsa tempo, si può fare lo stesso considerando la risorsa spazio, ovvero la memoria utilizzata. Per misurarla si utilizzerà una MdT M, e in particolare:
- se M è
deterministica, allora la sua spazio complessità è la funzione f(n), cioè il massimo numero di celle del nastro su cui M farà uno scan per ogni ingresso di lunghezza n;
- se M è
non deterministica (da ora, n.d.), allora la sua spazio complessità f(n) sarà il numero massimo di celle del nastro su cui M farà uno scan per ogni ramo della sua computazione e per ogni ingresso di lunghezza n.
Quella che ci interessa è però la stima asintotica della spazio-complessità, che può essere così definita:
Sia f:N->R+ una funzione. Le classi di spazio complessità, SPACE(f(n)) ed NSPACE(f(n)), sono definite come segue:
- SPACE(f(n)) = {L|L è un linguaggio deciso da una MdT deterministica O(f(n))-spazio}
- NSPACE(f(n)) = {L|L è un linguaggio deciso da una MdT
n.d. O(f(n))-spazio}
Esempio 1: SAT è spazio-lineare?
Sappiamo che il problema SAT è NP-completo, e che quindi non può essere risolto con una MdT deterministica in tempo polinomiale. Figurarsi se ci riesce in tempo lineare. Lo spazio ha però una caratteristica vincente rispetto al tempo: può essere riutilizzato!
L'idea per la nostra MdT che risolve il problema SAT in spazio lineare, è quella di assegnare una cella ad ogni variabile, e riutilizzarla ogni volta che facciamo un nuovo assegnamento:
M = "su ingresso Φ: (dove Φ è una formula booleana)
1. per ogni valore di verità assegnato alle variabili x
1..x
n di Φ:
2. valuta Φ sull'assegnamento;
3. se Φ=1 in almeno un assegnamento, allora ACCETTA; altrimenti RIFIUTA."
M è evidentemente spazio-lineare, perché ad ogni iterazione utilizza sempre lo stesso spazio in memoria, lineare al numero di variabili. Dato che tale numero è al più pari ad n, la lunghezza dell'ingresso, allora possiamo dire che la macchina è eseguita in O(n)-spazio.
Esempio 2: (not)ALL è spazio-lineare?
Consideriamo ora un problema risolvibile con una MdT n.d., il problema ALLNFA, che deve stabilire se un determinato linguaggio accetta tutte le stringhe. Più formalmente:
ALLNFA = {<A> | A è un NFA ed L(A)=Σ*}
A noi non interessa il problema ALLNFA, ma il suo complementare, di cui vogliamo trovare una MdT n.d. spazio-lineare che lo risolva. L'idea è quella di usare il non determinismo per trovare una stringa che sia rifiutata dall'NFA, ed usare uno spazio lineare per tenere traccia degli stati in cui l'automa può trovarsi in un determinato momento. Lineare a cosa? Semplice: al numero q di stati in cui può trovarsi l'NFA, di cui ricordiamo possono esserne contemporaneamente attivi 2q, ognuno rappresentato con un simbolo.
Scriviamo la MdT N:
N = "su ingresso <M>: (dove <M> è un NFA)
1. metti un marker sullo stato iniziale dell'NFA;
2. ripeti 2
q volte:
3. seleziona in modo
n.d. un simbolo d'ingresso e aggiorna le posizioni dei
marker sugli stati di M;
4. se nessun marker è su uno stato accettante, allora ACCETTA; altrimenti RIFIUTA."
Si noti che il passo 3 non fa altro che simulare la lettura del simbolo selezionato in modo n.d..
Per come è stato costruito N, l'unico spazio di cui ha bisogno è quello per memorizzare le posizioni dei marker e per il contatore del ciclo descritto ai passi (2) e (3). Si tratta quindi di uno spazio lineare all'ingresso, perché ad ogni iterazione andrò a scrivere sempre sulle stesse celle di memoria!
Teorema di Savitch
La MdT deterministica che simula la corrispondente n.d. ha una complessità tempo esponenziale rispetto al suo modello. Il teorema di Savitch dimostra invece che nello spazio la complessità non aumenta allo stesso modo, ma molto meno.
Per ogni funzione f:N->R+, dove f(n)>=n,
Dimostrazione
La situazione: partiamo con una MdT n.d. f(n)-spazio, e dobbiamo simularla in modo deterministico sapendo che con quella si potranno avere più scelte per ogni nodo.
Una prima idea è simulare tutti i possibili rami della n.d., ma così facendo non potremo sovrascrivere l'area di memoria utilizzata, perché dobbiamo tenere traccia di quale ramo termina e quale no; con questa strategia si userebbe quindi uno spazio esponenziale, e non va bene.
La soluzione è introdurre un nuovo problema, quello che ci permette di verificare se una MdT n.d. può passare da una configurazione iniziale c1 a quella finale c2 in un numero di passi minore o uguale a t. Chiamiamo questo secondo problema yieldability problem, e lo risolviamo definendo la MdT deterministica e ricorsiva CANYIELD.
Arriviamo al dunque.
Data una MdT n.d. N che decide un linguaggio A in uno spazio f(n), costruiamo la MdT deterministica M che utilizzando la procedura CANYIELD riesca a decidere A. N avrà come input la stringa w da verificare, mentre CANYIELD riceverà in ingresso le due configurazioni c1 e c2 , ed il numero massimo di passi impiegabili t.
CANYIELD = "su ingresso c1, c2, t:
- se t=1, verifica se c1=c2 o se c1->c2 in un unico passo in accordo alle regole di N. Se uno dei due test va a buon fine, ACCETTA; altrimenti RIFIUTA;
2. se t>1, per ogni configurazione c
m di N su w che usa spazio f(n);
3. esegui CANYIELD su ingresso c1, cm, t/2;
4. esegui CANYIELD su ingresso cm, c2, t/2;
5. se (3) e (4) vanno entrambi a buon fine, allora ACCETTA; altrimenti RIFIUTA."
Passiamo ora a definire la MdT M che simula N, e per farlo introduciamo alcuni accorgimenti:
- quando N accetta pulisce l'intero contenuto del nastro e lo sostituisce con la configurazione caccept;
- chiamiamo cstart la configurazione iniziale di N sulla stringa d'ingresso w;
- selezioniamo una costante d tale che N non abbia un numero di configurazioni maggiore di 2d*f(n), dove n è la lunghezza di w. In questo modo fissiamo un limite superiore al tempo di computazione per ogni ramo, e creiamo un legame tra numero di configurazioni possibili e tempo.
M = "su ingresso w:
- restituisci il risultato di CANYIELD(cstart, caccept,2d*f(n))."
Dato che CANYIELD risolve sicuramente l'yieldability problem, possiamo affermare che M simula correttamente N. Non ci resta che fare l'analisi dell'algoritmo e verificare se M è eseguito in O(f2(n)) spazio, come sostiene il teorema. Cosa dobbiamo fare? Calcolare quanto spazio richiede ogni ricorsione di CANYIELD e moltiplicarlo per il numero di ricorsioni stesse.
Ogni volta che CANYIELD invoca sé stesso ricorsivamente, memorizza il numero di stato corrente e i valori di c1 c2 e t su uno stack, così che possano essere ripristinati una volta tornati dalla chiamata ricorsiva. Ogni livello di ricorsione richiede quindi uno spazio addizionale O(f(n)).
Considerato che ad ogni ricorsione dimezziamo il numero di passi impiegabili t, e che inizialmente t è pari a 2d*f(n), il numero di ricorsioni è:
O(log2d*f(n)) = O(d*f(n)) = O(f(n))
Quindi, spazio richiesto ad ogni ricorsione per il numero di ricorsioni:
O(f(n)) * O(f(n)) = O(f2(n)), come sostenuto dal teorema di Savitch.
Classe PSPACE e PSPACE-completezza
PSPACE è la classe di linguaggi decidibili in spazio polinomiale usando una MdT deterministica. In altre parole:
Analogamente, NPSPACE sarà la classe di linguaggi decidibili in spazio polinomiale usando una MdT n.d.. Si noti che per il teorema di Savitch è possibile simulare una MdT deterministica spazio-polinomiale con una MdT n.d. anch'essa spazio-polinomiale. Quindi possiamo affermare che NPSPACE=PSPACE, al contrario di quanto avviene per la tempo-complessità.
Per quanto riguarda la completezza, possiamo affermare che:
Un linguaggio B è PSPACE-completo se soddisfa due condizioni:
- B è in PSPACE;
- Ogni A in PSPACE è riducibile in tempo polinomiale a B.
Se B soddisfa solo la seconda condizione è chiamato PSPACE-hard.
Perché parliamo di tempo riducibilità e non di spazio riducibilità? Ma per non complicarci troppo la vita, belin! Life is too short! (i problemi completi sono i più difficili di tutti, ed una volta che abbiamo verificato che è in PSPACE chi se ne frega se consideriamo la riducibilità nel tempo o nello spazio)
Teorema 1 - TQBF è PSPACE-completo?
Una "formula booleana" è un'espressione che contiene variabili booleane, costanti 0 e 1, e gli operatori booleani AND, OR e NOT.
Una "formula booleana quantificata" è una formula booleana che contiene quantificatori universali o esistenziali (o entrambi), ognuno dei quali ha una variabile nel proprio scope.
Una "formula booleana completamente quantificata" (TQBF) è una formula booleana quantificata in cui ogni variabile compare nello scope di un quantificatore.
Una "formula soddisfacibilmente booleana completamente quantificata" non esiste, me la sono inventata ora, ma era divertente continuare ad aggiungere parole.
Il problema TQBF consiste nel determinare se una formula booleana completamente quantificata sia vera. Più formalmente:
TQBF = {Φ | Φ è una formula booleana completamente quantificata vera}
Ed ecco l'agognato teorema da dimostrare:
Dimostrazione
La prima condizione da verificare è che TQBF sia in PSPACE, cioè se è risolvibile in uno spazio polinomiale con una MdT deterministica. Vediamo se questa va bene:
T = "su ingresso Φ: (dove Φ è una formula booleana completamente quantificata)
- se Φ non ha quantificatori vuol dire che è un'espressione con sole costanti, quindi valuta Φ è ACCETTA se è vera; altrimenti RIFIUTA;
- se Φ è uguale a ∃x φ, chiama ricorsivamente T su φ, prima sostituendo 0 a x e poi sostituendo 1 a x. Se uno dei due risultati è accettato, allora ACCETTA; altrimenti RIFIUTA;
- se Φ è uguale a ∀x φ, chiama ricorsivamente T su φ, prima sostituendo 0 a x e poi sostituendo 1 a x. Se entrambi i risultati sono accettati, allora ACCETTA; altrimenti RIFIUTA."
L'algoritmo T decide TQBF ed usa uno spazio polinomiale, perché è lineare al numero m di variabili di Φ date in ingresso (spazio usato: O(m)).
La seconda condizione da verificare è che qualunque problema A in PSPACE possa essere ridotto in tempo polinomiale a TQBF. In altre parole, dato un linguaggio A deciso da una MdT M deterministica (tempo esponenziale) in spazio polinomiale, dobbiamo verificare se è possibile mappare una stringa w in una formula booleana completamente quantificata Φ che sia vera se e solo se M accetta w. Non avete anche voi una sorta di deja-vu? Quello che abbiamo appena detto non ha vaghe somiglianze col problema di Cook-Levin ("SAT è NP-completo")? Essì, qualcosa in comune c'è, vediamo dove ci porta questa strada. Dobbiamo costruire una formula Φ che simuli M su un ingresso w esprimendo i requisiti che dovrebbe avere un tableau accettante. Abbiamo un problema però: in Cook-Levin il tableau è nk x nk, mentre in questo caso avremmo larghezza nk (lo spazio usato da M) ma altezza esponenziale dato che M può essere eseguito in tempo esponenziale. Merda: per rappresentare un tableau di dimensione esponenziale dovremo usare una formula con una dimensione altrettanto esponenziale, esattamente il risultato che non vogliamo ottenere da una riduzione tempo polinomiale.
Ci viene in aiuto il teorema di Savitch, grazie al quale possiamo dimezzare ad ogni iterazione lo spazio entro cui cercare la soluzione. Riusciamo così a compattare la dimensione esponenziale (che otterremmo applicando paro-paro Cook-Levin) in una polinomiale. La formula di compattamento è questa:
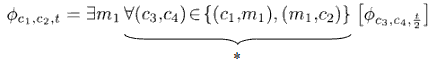
Dove, per qualsiasi coppia (c3,c4), * può essere uguale sia a (c1,m1) che a (m1,c2), quindi sto considerando contemporaneamente la metà superiore e quella inferiore della formula.
Alla prof non interessa che si dimostri (o capisca) come si è arrivati a questa formula, l'importante è credere che sia giusta. Per quanto riguarda la complessità, si tratta di una formula ricorsiva in cui:
- lo spazio usato da ogni ricorsione è lineare alla dimensione della configurazione, quindi è O(f(n));
- il numero di ricorsioni è pari a log(2d*f(n)), quindi O(f(n)).
Ne deriva che la complessità della formula è O(f2(n)), che è polinomiale e quindi soddisfa la seconda condizione da verificare.
Il teorema è dunque dimostrato: TQBF è PSPACE-completo.
Teorema 2 - FORMULA-GAME è PSPACE-completo?
In generale, per gioco si intende una competizione in cui i partecipanti devono raggiungere un certo obiettivo rispettando una serie di regole.
Il FORMULA GAME è un gioco elettrizzante con tutti gli ingredienti per diventare il successo più frizzante dell'estate: quantificatori e valori di verità di formule booleane.
La formula Φ con cui si gioca ha questo aspetto:
Φ = ∃x1 ∀x2 ∃x3 ... Qxk [φ]
, dove Q è un quantificatore universale o esistenziale e φ il resto della formula senza quantificatori (ma con le variabili che si trovano nei loro scope).
Ci sono due giocatori, che giocano a turni alternati:
- giocatore E, che deve dare un valore di verità a tutte le variabili con quantificatore esistenziale. Vince se il valore finale della Φ è pari a 1;
- giocatore A, che deve dare un valore di verità a tutte le variabili con quantificatore universale. Vince se il valore finale della Φ è pari a 0.
Ad esempio, sia data questa formula:
Il giocatore E inizia per primo e dovrà assegnare un valore alla variabile x1. Siccome il suo scopo è fare in modo che la formula risulti pari a 1, per come questa è costruita dovrà riuscire a ottenere un 1 in tutte le sottoformule messe in AND tra loro. Assegnando x1=1 si assicura un 1 nella prima sottoformula.
Tocca ora ad A, che dovrà intervenire su x2. Il suo scopo è fare in modo che almeno una sottoformula abbia valore 0, così che messa in AND con le altre renda la formula globale pari a 0. Ha senso perciò che assegni x2=0. Si noti però che così facendo ha fatto finire un 1 nella terza sottoformula, in cui era presente la negazione della stessa variabile x2.
L'ultimo turno spetta ad E, per cui è vita facile assegnare x3=1 e vincere la partita.
Da tutto questo appare evidente che i giocatori non scelgono a caso i valori, ma adottano una strategia. In particolare diciamo che un giocatore ha una strategia vincente per una partita quando entrambi i contendenti giocano in modo ottimale e riesce comunque a vincere.
Il problema del FORMULA-GAME può essere così definito:
FORMULA-GAME = {φ | il giocatore E ha una strategia vincente nel formula-game associato a φ}
Il teorema da dimostrare è il seguente:
FORMULA-GAME è PSPACE-completo.
Dimostrazione
Invece di dimostrare le due condizioni della PSPACE-completezza possiamo provare a dimostrare che il problema è formulato in modo analogo ad un altro problema PSPACE-completo.
In effetti a pensarci bene FORMULA-GAME è riconducibile a TQBF: la strategia vincente di E è quella che lo porta a rendere la formula pari a 1, esattamente lo stesso scopo di TQFB che vuole che la formula booleana completamente quantificata sia vera. Inoltre in entrambi i casi si interviene sull'assegnamento di valori 0/1 alle variabili, anche se in un caso con l'obiettivo di vincere e nell'altro per provare la soddisfacibilità.
Poche balle: dato che una formula φ appartiene a TQBF quando φ appartiene a FORMULA-GAME, il teorema è dimostrato dalla stessa dimostrazione di TQBF.
L e NL
Se pensavate che usare spazi lineari poteva soddisfarci vi sbagliavate di grosso. Da questo momento studieremo limiti di spazio sotto-lineari (logaritmici), in cui la macchina legge l'intero ingresso ma non ha spazio sufficiente per memorizzarlo tutto. Va da sé che si tratta di un concetto inapplicabile al tempo, perché significherebbe non avere il tempo di leggere l'intero ingresso.
Per capire meglio la situazione dovremo cambiare modello computazionale: una MdT con due nastri, uno di sola lettura (per gli ingressi) e l'altro di lettura/scrittura (di lavoro). Gli ingressi dovranno rimanere sempre sul primo nastro, mentre sarà quello di lavoro che contruibirà alla spazio complessità della MdT. A queste condizioni possiamo affermare che:
L è la classe di linguaggi che sono decidibili in spazio logaritmico su una MdT deterministica. In altre parole: L=SPACE(logn).
NL è la classe di linguaggi che sono decidibili in spazio logaritmico su una MdT n.d.. In altre parole: NL=NSPACE(logn).
Si noti che il dilemma "L=NL ?" è analogo a quello "P=NP ?".
Esempio L
Come esempio di linguaggio in L consideriamo A={0k1k | k>=0}.
Una MdT che lo descrive potrebbe essere:
M = "su ingresso w: (dove w è una stringa)
1. fai uno scan del nastro e RIFIUTA se c'è uno 0 a destra di un 1;
2. ripeti finché ci sono sia 0 che 1 sul nastro:
3. fai uno scan del nastro, marcando un singolo 0 e un singolo 1;
4. se rimangono degli 0 non marcati mentre tutti gli 1 lo sono (o viceversa),
allora RIFIUTA; altrimenti ACCETTA."
Lo spazio richiesto da M è però lineare al numero di caratteri, quindi non va bene.
Dato però che con una MdT possiamo realizzare qualsiasi funzione eseguibile da un elaboratore, ne potremmo definire una che lavora come contatore. La nostra MdT spazio logaritmica userà allora due contatori, uno per gli 0 e uno per gli 1, e scriverà i risultati sul nastro di lavoro per fare un confronto: se i numeri sono uguali, allora ACCETTA; altrimenti RIFIUTA. Rispetta i requisiti di L? Sì, perché la rappresentazione in binario del numero che quantifica la dimensione di una stringa di caratteri (gli 0 e gli 1) è logaritmica alla dimensione stessa. Sopracciglio alzato? Facciamo un esempio di stringa di 30 caratteri, e subito sotto il numero binario che ne indica la dimensione:
000000000000000000000000000000
11110
Un bel risparmio di spazio, no?!
Quindi A appartiene alla classe L.
Esempio NL
Nel capitolo sulla Complessità nel tempo abbiamo dimostrato che il problema PATH è in P. Ora vogliamo vedere se è anche in NL.
Dato un grafo diretto G, il problema PATH ha come obiettivo quello di determinare se esiste un percorso diretto tra due nodi s e t. Più formalmente:
PATH = {<G,s,t> | G è un grafo diretto che ha percorso diretto tra s e t}
Supponiamo di avere una MdT n.d., e selezioniamo in modo n.d. un nodo collegato ad s, memorizzandolo (solo lui) sul nastro. Ripetiamo l'operazione sull'ultimo nodo selezionato, andando a sovrascrivere l'identificativo del nuovo nodo estratto in modo n.d.. Continuiamo a ciclare finché non si è raggiunto il nodo t, o finché il numero di iterazioni non sia maggiore del numero dei nodi (così da escludere loop infiniti su un percorso).
Questo algoritmo garantisce la soluzione del problema in uno spazio logaritmico, quindi PATH è in NL.
NL-completezza
Dopo NP-completezza e PSPACE-completezza, non potevamo perdere la ghiotta occasione di parlare di NL-completezza.
In generale possiamo dire che un linguaggio è NL-completo se è in NL e se ogni altro linguaggio in NL è riducibile al linguaggio considerato. La riducibilità non può però avvenire in tempo-polinomiale (tutti i problemi sotto-lineari come il nostro sono risolvibili in tempo-polinomiale), ma dobbiamo introdurre un nuovo tipo di riducibilità, quella spazio-logaritmica.
Un trasduttore spazio logaritmico è una MdT con un nastro in sola lettura (ingressi), uno in sola scrittura (uscite) ed uno di lavoro in lettura/scrittura. Il nastro di lavoro può contenere O(logn) simboli. Un trasduttore spazio logaritmico M computa una funzione f:Σ*->Σ*, dove f(w) è la stringa che rimane sul nastro di uscita al termine di M eseguito su ingresso w. Chiamiamo f log space computable function. Il linguaggio A è spazio-logaritmico riducibile a B, scritto A≤LB, se A è mapping riducibile a B utilizzando una log space computable function f.
Ora possiamo definire la NL-completezza:
Un linguaggio B è NL-completo se soddisfa due condizioni:
- B è in NL;
- Ogni A in NL è spazio-logaritmico riducibile a B.
Ciliegina sulla torta, citiamo due teoremi sulla NL-completezza (che non dimostreremo).
Se A≤LB e B appartiene ad L, allora A appartiene ad L.
Il corollario è la solita speranzosa strada da battere per verificare se L=NL:
Se un linguaggio NL-completo è in L, allora L=NL.
Teorema 3 - PATH è NL-completo?
Dimostrazione
La prima condizione da verificare è che PATH sia in NL, e l'abbiamo dimostrato poche righe fa nel paragrafo "Esempio NL".
La seconda condizione da verificare è che ogni A in NL sia spazio-logaritmico riducibile a PATH. In altre parole, dato un linguaggio A deciso da una MdT M in spazio logaritmico, dobbiamo verificare se è possibile mappare una stringa w in un grafo G che abbia un percorso diretto tra s e t se e solo se M accetta w.
L'idea dietro la riduzione spazio logaritmica da A a PATH è quella di costruire un grafo che rappresenti la computazione della MdT n.d. spazio logaritmica che risolve A. Basterà dunque far corrispondere ad ogni configurazione di M un nodo del grafo, ed unirne due con un arco se e solo se esiste una transizione possibile (permessa dalle funzioni di transizione del linguaggio) che giustifichi il passaggio da una configurazione all'altra. In tutto questo avremo premura di far corrispondere al nodo s la configurazione iniziale di M, e a t quella terminale accettata.
Ora che sappiamo come ridurre, dobbiamo dimostrare che riusciamo a farlo utilizzando un trasduttore spazio logaritmico. Nel nastro in sola lettura ci mettiamo l'ingresso w, e su quello di uscita la descrizione di G, composta da una lista di nodi e una lista di archi. Per verificare se si può passare da una configurazione all'altra (quindi il controllo degli archi) posso memorizzare solo le celle intorno la testina, perché sono le uniche che cambieranno (dunque le uniche con informazioni utili). In questo modo si riesce ad utilizzare uno spazio logaritmico rispetto alla dimensione dell'ingresso w, dimostrando perciò la seconda condizione.
Poiché entrambe le condizioni sono rispettate, possiamo affermare che PATH è NL-completo.
Torna alla pagina di Informatica Teorica