Torna alla pagina di Sistemi Intelligenti
:: Sistemi Intelligenti - Appunti del 7 Ottobre ::
La lezione di oggi è stata tenuta - in via sempre meno eccezionale - dal prof Ferrari.
Portiamo avanti il discorso iniziato ieri sulle reti neurali feed-forward, che grazie alla loro flessibilità sono tra le architetture più utilizzate.
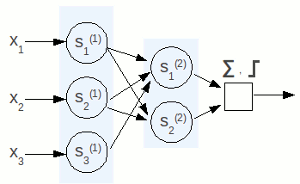
Sappiamo già che in queste reti i neuroni sono organizzati in strati detti layer, e che l'informazione passa da uno all'altro seguendo un'unica direzione. Distinguiamo sostanzialmente tre strati, ognuno caratterizzato dalla stessa funzione di attivazione e quindi la stessa reazione agli stimoli:
La prima rete feed-forward realizzata è anche la più semplice, ed è il percettrone. Nel percettrone l'uscita viene generata pesando gli ingressi e applicando al risultato un sogliatore.
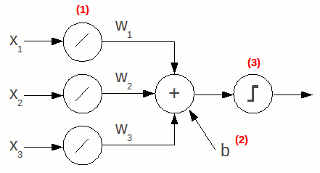
Facendo riferimento ai numeri in rosso dello schema accanto:
Per convenzione i pesi e gli ingressi sono organizzati in vettori, indicati con il simbolo in grassetto: w è il vettore dei pesi, x quello degli ingressi.
Varrà quindi la seguente formula: w * x = Σi wi * xi
Altra formula interessante è: w * x + b = Σi wi * xi + 1 * b
Questa equazione ribadisce il concetto espresso prima al punto (2), ovvero che la costante di calibrazione del percettrone può essere considerata come peso (wn+1) di un nuovo ingresso (xn+1) che ha valore pari ad 1.
Una proprietà geometrica che si rivelerà presto importante è che "w * x + b" identifica un iperpiano nello spazio dei reali Rn+1. Per capire l'importanza basta vedere com'è fatta la funzione di uscita della rete:
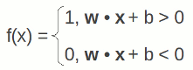
Alla luce di quanto detto poco fa, possiamo affermare che tutti i punti di ingresso che si trovano sopra l'iperpiano avranno come risposta 1, altrimenti avranno risposta 0. Grazie al lavoro del sogliatore lineare binario si ottengono dunque due classi.
I pesi del percettrone sono configurati (fase di addestramento) con un algoritmo che prevede l'apprendimento per esempi. Si tratta in questo caso di coppie di esempi (ingressi e uscite) della classificazione che si vorrebbe ottenere, che nel loro insieme andranno a formare il cosiddetto dataset. In questo modo si insegna al percettrone come rispondere.
Vediamo come funziona l'algoritmo. Per ogni coppia di ingressi-uscite (xi, yi) vengono modificati i parametri interni w e b secondo due formule. La prima:
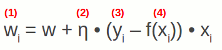
Dove:
Il concetto espresso è questo: "se l'uscita attuale è vicina a quella che mi aspetto allora non tocco nulla, altrimenti modifico i pesi in modo proporzionale agli ingressi".
La seconda formula è invece: bi = b + η (yi - f(xi))
Il percettrone permette di realizzare un numero limitato di applicazioni, in particolare riesce a implementare solo funzioni linearmente separabili (come l'AND o l'OR, ma non lo XOR). Questo limite discende direttamente dalla funzione di attivazione sopra riportata, e per meglio capire il concetto consideriamo la seguente funzione bidimensionale:
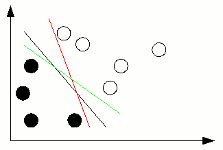
I pallini presenti nel grafico individuano le coppie di valori ingresso-uscita di alcuni esempi, e il colore di riempimento indica la loro classificazione. Poiché è possibile in questo caso tracciare un buon numero di linee rette che separino le due aree di valori, la funzione è linearmente separabile. Le rette rappresentano una delle soluzioni che il percettrone ha trovato per distinguere le classi partendo dagli esempi forniti nel dataset.
Riportiamo ora il grafico dello XOR:
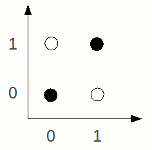
Come si può facilmente vedere in questo caso non è possibile separare le due classi di valori con una retta. Per realizzare uno XOR non ci resta che abbandonare la via del percettrone, e utilizzare modelli multistrato (che vedremo nel prossimo capitolo).
Ultima considerazione per l'addestramento è che il dataset va scelto bene. Questa situazione ad esempio contiene un errore:
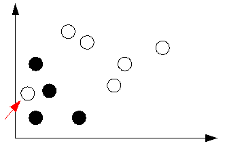
Il valore indicato dalla freccia rossa non è affidabile, e può essere dovuto o a un errore o a un imprevisto occorso durante la costruzione dell'insieme degli esempi. Non è affatto raro che tale fenomeno avvenga, ma non bisogna preoccuparsi perché la rete neurale è un'architettura robusta, capace di ignorare o tenere in scarso conto gli errori nel dataset. Questa proprietà è detta generalizzazione, e ha il vantaggio di poter essere settata (ad esempio nel caso dello XOR deve essere azzerata, perché il fatto di essere non linearmente separabile non è dovuto a errori ma alle caratteristiche intrinseche della funzione).
Le prime reti neurali multistrato risalgono agli anni '80, e tra le loro caratteristiche: hanno due o più strati (evidentemente), possono avere funzioni di attivazione non lineari, sono in grado di realizzare qualsiasi funzione, sono configurabili con algoritmi di backpropagation dell'errore.
La rete funziona sempre portando il segnale in avanti, finché non si arriva all'ultimo strato in cui facciamo la differenza tra il risultato desiderato e quello ottenuto. Il risultato di questa operazione rappresenta l'errore, e lo rimandiamo all'inizio della rete così che possa essere tenuto in considerazione per i nuovi calcoli.
Consideriamo ora la cosa da un punto di vista grafico. Ammettiamo di conoscere l'andamento dell'errore (er) rispetto ad un certo parametro (par) secondo questa forma:
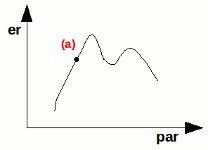
Se sappiamo di essere nel punto (a), possiamo chiederci in che direzione dovremmo muoverci per migliorare la soluzione: aumentiamo o diminuiamo il valore del parametro? Per decidere basta calcolare la derivata della funzione in quel punto e regolarci in base ad essa. Nell'esempio sopra ci spoteremo verso sinistra.
Introduciamo a questo punto il problema dei minimi locali, che abbiamo già accennato all'inizio della lezione. Per capirli facciamo un nuovo esempio:
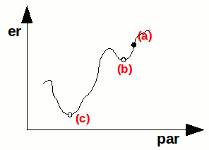
Se ci troviamo nel punto (a) è logico immaginare che ci sposteremo nel punto (b) e qui ci fermeremo, anche se in (c) si avrebbe una soluzione migliore.
Altro problema: di quanto ci dobbiamo spostare a destra o a sinistra? Se troppo poco rischiamo di rimanere bloccati in un punto, se troppo rischiamo di saltare dei minimi appetitosi. La scelta non è affatto banale.
Ricapitolando, se localmente so decidere con una certa facilità in che verso muovermi, non so né di quanto e né se ci potrebbero essere soluzioni locali migliori (magari dei minimi globali).
A tutto questo si tenta di far fronte con la tecnica del gradiente e con la backpropagation.
Il problema è che da questo momento in poi il professore è andato un po' in crisi, ed io con lui. Se qualcuno ha preso appunti decenti, prego di postarli ;)