Torna alla pagina di Sistemi Operativi
:: Appunti 2.0 ::
Implementazione del file system
Il file system risiede permanentemente in un' unità di memorizzazione secondaria, ovvero su un disco in grado di contenere una grande quantità di dati anche in assenza di alimentazione. Su tali supporti è possibile riscrivere i file sempre nella stessa locazione e si può accedere a qualsiasi blocco di informazioni in modo sia sequenziale che diretto. I dischi si dimostrano dunque una scelta particolarmente efficace per la memorizzazione. Per migliorare ulteriormente l'efficienza dell'I/O i trasferimenti tra memoria centrale e secondaria vengono effettuati in blocchi costituiti da più settori.
Quando si progetta un file system bisogna valutare attentamente come dovrà apparire all'utente e bisogna studiare quali algoritmi e strutture dati si dimostrano più idonei per mappare la struttura logica nei dispositivi fisici.
Il file system è composto da vari livelli, ognuno dei quali sfrutta le funzionalità di quelli sottostanti. Al livello più basso c'è il controllo I/O, composto dai driver del dispositivo e dai gestori delle interruzioni. I primi si occupano delle traduzioni delle istruzioni ad alto livello in un linguaggio comprensibile alla macchina, i secondi vengono invece utilizzati per trasferire le informazioni tra memoria centrale e i dispositivi.
Abbiamo poi il file system di base, che invia comandi generici al dispositivo interessato per leggere e scrivere nei blocchi fisici (identificati con l'indirizzo numerico del disco).
Il livello superiore è il modulo di organizzazione dei file, che oltre a gestire l'organizzazione dei blocchi fisici in modo da ricostruire ogni file traducendo gli indirizzi si coordina col gestore dello spazio libero.
Infine c'è il file system logico che si occupa dei metadati, ovvero tutte le strutture del file system eccetto il contenuto dei file. Gestisce la struttura della directory e la struttura di ogni file tramite il blocco di controllo di file, ed è responsabile anche della loro protezione e sicurezza.
Per realizzare un file system vengono utilizzate diverse strutture su disco e in memoria, che possono variare sensibilmente a seconda del sistema operativo. Su disco abbiamo:
Le informazioni in memoria centrale sono usate sia per la gestione del file system che per il miglioramento delle prestazioni tramite la cache. Abbiamo le seguenti strutture:
Per creare un nuovo file il programma fa una chiamata di sistema al file system logico che, una volta assegnatogli un nuovo descrittore, carica nella memoria centrale la directory appropriata e la aggiorna con il nome e il descrittore del nuovo file. A questo punto riscrive la directory anche in memoria secondaria.
Per poter essere utilizzato in operazioni di I/O il file deve essere aperto con la open(), che subito verifica se si trova nella tabella dei file aperti di sistema. Se c'è, si crea un puntatore nella tabella del processo a quella generale; altrimenti il file system cerca il file e ne copia il descrittore nella tabella di sistema, che referenzierà con un puntatore nella tabella del processo. Il puntatore con cui vengono effettuate tutte queste operazioni si chiama descrittore del file o file handle.
Quando un processo chiude il file si rimuove l'elemento dalla tabella del processo e viene decrementato di uno il contatore associato al file nella tabella di sistema dei file aperti; in particolare se il valore di tale contatore arriva a 0, si rimuove l'elemento anche dalla tabella generale.
Ogni partizione può essere formattata o grezza a seconda che contenga o meno un file system. Il disco grezzo si usa quando non c'è un file system adatto all'uso che si vuol fare della partizione, ad esempio un'area di swap, o un'area di memoria per un database, o ancora informazioni per dischi RAID, ecc.
Le informazioni sull'avvio del sistema possono essere mantenute in una partizione separata dato che in quella fase non sono ancora caricati i driver del file system. In questa partizione vengono generalmente mantenute una sequenza di istruzioni sul come caricare il sistema operativo, o più di uno se c'è un loader che permette il dual-boot.
La partizione radice (root partition) contiene il kernel del sistema operativo più altri file di sistema e viene montata anch'essa all'avvio; tutte le altre partizioni possono essere montate automaticamente di seguito a queste o manualmente più tardi.
Durante il montaggio viene verificato che il file system sia valido e compatibile, e se non lo è bisogna controllare la coerenza della partizione ed eventualmente correggerla. Se tutto va buon fine non rimane che annotare nella tabella di montaggio in memoria quanti e quali tipi di file system sono presenti. Windows li indica con lettere seguite dal due punti.
Come integrare nello stesso sistema file system di tipo diverso in modo trasparente all'utente? Semplice: isolando le funzionalità delle chiamate di sistema dai dettagli di realizzazione, implementando il file system in tre strati principali: interfaccia (con le chiamate open, read, write e close più i descrittori), file system virtuale e quelli locali o remoti.
Il file system virtuale (VFS) ha due funzioni:
Quello della lista è il metodo più semplice per realizzare una directory: una lista dei nomi dei file con puntatori ai blocchi dei dati. Lo svantaggio è però la necessità di effettuare una ricerca lineare nella lista quando si vuole trovare un file, o aprirlo o cancellarlo. Questa ricerca implica un costo computazionale non indifferente, riducibile con una cache o ordinando la lista (anche se in questo caso ciò che risparmio nella ricerca lo impegno per l'ordinamento) ma senza risultati entusiasmanti.
Per gestire gli elementi cancellati dalla lista si può scegliere di marcarli per individuare più facilmente gli spazi disponibili, oppure si può spostare l'ultimo elemento negli spazi liberati così da ottenere le minori dimensioni possibili.
Alla lista degli elementi di una directory si può affiancare una tabella di hash, che permette di ridurre notevolmente i tempi di ricerca prendendo il nome del file e - applicando una funzione - restituendo un puntatore nella lista lineare.
Avendo ridotto il numero di elementi da scandire questa tecnica appare più veloce, ma nasce il rischio di collisioni, cioè due file identificati dalla stessa posizione nella tabella. Per limitarne il numero è possibile aumentare le dimensioni della tabella o estenderla in una tabella di hash a overflow concatenato, in cui le collisioni vengono comunque rappresentate mettendo una lista nella cella anziché un valore unico.
Come allocare i file su disco nel modo più efficiente possibile? Abbiamo tre strategie: allocazione contigua, collegata o indicizzata. Qualche sistema le supporta tutte, ad esempio RDOS. Vediamole.
L' allocazione contigua prevede che ogni file occupi un certo numero di blocchi contigui su disco, quindi i loro indirizzi avranno un ordinamento lineare. E' definita dall'indirizzo di inizio (b) sul disco e dalla lunghezza in numero di blocchi.
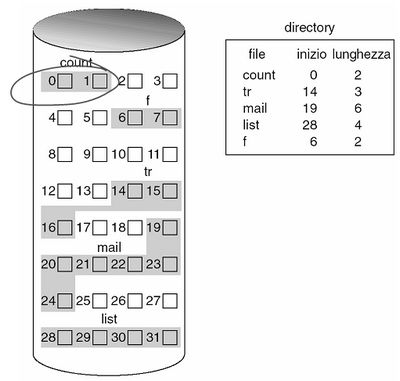
Offre buone prestazioni e consente sia l'accesso sequenziale che quello diretto, dato che per accedere al blocco i basta puntare al blocco b+i. Uno dei problemi di questo sistema è la difficoltà nel trovare uno spazio disponibile contiguo abbastanza grande da contenere il file, l'altro è che soffre di frammentazione esterna. Va inoltre considerato che non è sempre dato sapere quanto sarà grande un file, quindi può essegrli assegnato un numero di blocchi insufficiente (e se ne chiederà altri bisognerà terminare il programma o copiarlo in uno spazio più grande) o sovrastimato (con gli sprechi che comporta).
Esiste una variante che cerca di superare l'ultimo problema affrontato ed è l' allocazione contigua modificata, in cui quando un pezzo di memoria non si dimostra abbastanza grande per contenere il file si aggiunge un'estensione, ovvero un altro spazio di memoria contiguo che andrà collegato al blocco iniziale. Migliora le prestazioni ma vanno tenute sotto controllo le frammentazioni.
L' allocazione collegata supera tutti i problemi di quella contigua eliminando il problema della frammentazione e della crescita del file, facendo in modo che possa essere utilizzato qualsiasi blocco libero della lista dello spazio libero per le allocazioni. Ogni file è infatti una lista collegata di blocchi del disco, ognuno dei quali contiene il puntatore a quello successivo. La directory contiene un puntatore al primo e all'ultimo blocco del file e quindi si dimostra particolarmente adatta all'accesso sequenziale ma inefficiente per quello diretto dato che per trovare l'elemento i-esimo bisognerà scandirli tutti fino ad esso.
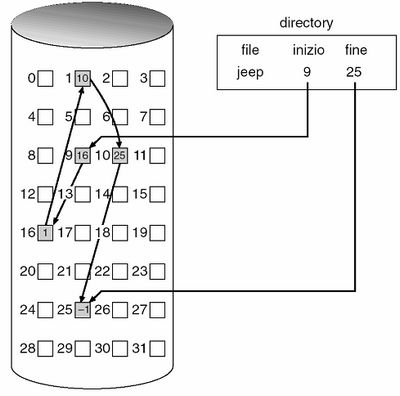
Il puntatore occupa uno spazio di memoria nel blocco che, per quanto piccolo, considerato nell'insieme diventa notevole. Per ridurre tale overhead si possono raggruppare più blocchi in unità dette cluster, che mantengono semplice la mappatura dei vari blocchi aumentando il rendimento del disco (meno ricerche) e la percentuale di spazio utilizzato per le informazioni e non per i puntatori. Ha come svantaggio il fatto di aumentare la frammentazione interna, ma questa dei cluster è un'ottima strategia adottata da molti sistemi operativi.
Consideriamo un altro problema, quello dell'affidabilità: cosa succederebbe se un puntatore fosse errato? Possiamo immaginarlo. Possibili soluzioni sono le liste a doppio collegamento o la scrittura del nome del file in ogni blocco (che però comporta maggior overhead).
La soluzione migliore è però un'importante variante dell'allocazione collegata, ed è la tabella di allocazione dei file (FAT) che viene memorizzata all'inizio di ogni partizione o in cache. Ha un elemento per ogni blocco ed è indicizzata in base al loro numero. L'elemento della directory contiene il numero di blocco del primo file; in sua corrispondenza è riportato il numero del blocco successivo e così via via fino all'ultimo elemento che ha un valore speciale di end of file. I blocchi liberi hanno invece valore 0.
Grazie alla FAT si ha un miglioramento del tempo di accesso diretto perché la testina del disco trova velocemente la locazione di qualsiasi blocco in essa.
L' allocazione indicizzata supera il problema di frammentazione esterna e della dichiarazione della dimensione del file introducendo il blocco indice (o i-node), cioè un array di indirizzi dei blocchi del file su disco. L'i-esimo elemento del blocco indice punta all'i-esimo blocco del file, mentre la directory contiene l'indirizzo del blocco indice stesso. Quando si crea un file tutti i puntatori sono impostati a nil, e questo valore sarà sostituito man mano che si allocheranno blocchi. A differenza della FAT che era unica per ogni partizione, con l'allocazione indicizzata ogni file ha la propria tabella indice.
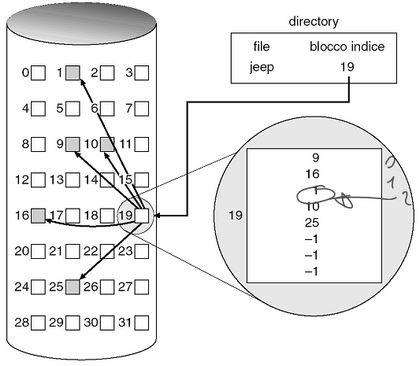
L'allocazione indicizzata supporta dunque con semplicità l'accesso diretto senza frammentazione esterna (perché può essere usato qualsiasi blocco) ed è affidabile (perché il malfunzionamento di un blocco non si riflette sulla coda), ma comporta uno spreco di spazio non indifferente dato che l'i-node rappresenta un overhead in generale maggiore di quello dovuto ai puntatori dell'allocazione collegata. Quanto deve essere grande allora? Troppo no o si sprecherebbe spazio, troppo piccolo nemmeno o non si riuscirebbe a contenere abbastanza puntatori per i file grandi. Il problema è risolvibile con tre tecniche diverse:
Si può aumentare la prestazione generale dell'allocazione indicizzata spostandone la gestione nelle cache.
I criteri da tenere in considerazione per decidere quali tecniche di allocazione adottare sono sostanzialmente l' efficienza di memorizzazione ed il tempo di accesso ai blocchi dati. Va inoltre considerato come avverrà l'accesso, se in modo diretto o sequenziale.
E' possibile combinare diversi tipi di allocazione cercando di sfruttare al meglio i vantaggi di ognuno. Ad esempio si può usare l'allocazione contigua per gli accessi diretti e la collegata per quelli sequenziali; oppure quella contigua per i file piccoli e quella indicizzata per i grandi, una soluzione che si è dimostrata particolarmente vantaggiosa.
Data la disparità crescente tra velocità della CPU e dei dischi si potrebbero sfruttare i tempi di allocazione per far eseguire alla CPU migliaia di istruzioni per ottimizzare i movimenti della testina, accelerando così i tempi.
Lo spazio su disco è limitato, dunque bisogna riutilizzare quello liberato dai file cancellati. E' necessario perciò mantenere una lista dello spazio libero in cui tener traccia di tutti i blocchi disponibili del disco, così da poterla consultare ogni qual volta si dovrà creare un nuovo file. Come implementarla?
La lista dello spazio libero viene spesso realizzata come mappa di bit (bit map) o vettore di bit (bit vector) in cui ogni blocco è rappresentato da un bit che se è libero vale 1, altrimenti 0. Il vantaggio di questo sistema è la sua semplicità ed efficienza nel trovare il primo blocco libero o n blocchi liberi consecutivi. Per contro si dimostra inefficiente se non è memorizzato in memoria centrale, il che rappresenta un problema per i grossi dischi dato che questi vettori sono piuttosto grandi.
Il sistema della lista collegata prevede di collegare tutti i blocchi liberi del disco tramite puntatori, e mantenendo un puntatore verso il primo blocco in una locazione speciale del disco o in una cache. Questo schema non è efficiente per l'attraversamento della lista, ma è piuttosto utile per trovare il primo blocco libero disponibile.
Il raggruppamento fa in modo che vengano memorizzati gli indirizzi di n blocchi liberi nel primo blocco libero. L'ultimo degli n blocchi segnalati contiene in realtà gli indirizzi degli n blocchi successivi e così via. Questo sistema permette, a differenza della lista collegata standard, di trovare più rapidamente i blocchi disponibili.
Col conteggio viene tenuta in memoria non solo l'indice del primo blocco libero, ma anche un contatore che indica il numero di blocchi liberi contigui. Ogni elemento richiede dunque più informazioni da registrare come overhead, ma la lista sarà sicuramente più corta.
Avere un occhio di riguardo per le prestazioni e l'uso efficiente del disco è fondamentale dato che stiamo parlando del componente più lento del computer. Bisogna evitare che esso diventi un collo di bottiglia.
L'uso efficiente dello spazio del disco dipende dagli algoritmi usati per l'allocazione. Ad esempio è conveniente sparpagliare gli inode per la partizione, permettendo così che i blocchi dati di un file abbiano più probabilità di essere vicini al proprio inode riducendo così i tempi di ricerca.
La frammentazione interna dei cluster si può ridurre facendo in modo che le loro dimensioni si riducano man mano che il file si ingrandisce. Alcuni sistemi operativi applicano questa tecnica.
Altri fattori critici sono le dimensioni di blocchi, puntatori e metadati, il cui valore deve essere valutato in base alla tecnologia adoperata e alla modalità d'uso.
Una volte scelte le procedure di base del file system ci sono ancora margini di miglioramento per le prestazioni. Alcune tecniche software sono la progettazione e l'impiego di algoritmi semplici ed efficaci e strutture dati ad accesso veloce. Fare in modo ad esempio che venga messa in memoria centrale la tabella degli inode aumenterà la rapidità di accesso alle sue informazioni.
Esistono poi vari tipi di supporti hardware dedicati all'accesso ai dischi:
Che stia mettendo in cache blocchi o pagine, l'algoritmo di sostituzione LRU è il più performante. In particolare è cosa ragionevole assegnare alla paginazione la più alta priorità, o in sistemi con alto tasso di I/O la cache sarebbe oberata di richieste di pagina e la paginazione andrebbe a scapito dei processi. La cache usata per le I/O rende tali operazioni più efficienti, soprattutto quando permette di schedulare le richieste in modo da muovere la testina il meno possibile. Comporta però particolare attenzione per le scritture asincrone da cache a disco (quelle più frequenti) perché in caso di guasto del sistema potrebbero esserci processi che non trovano alcuni file che invece in memoria centrale sembrano assegnati. Per alcuni dati critici si può dunque imporre la scrittura sincrona.
Per accessi sequenziali l'algoritmo LRU può dimostrarsi molto poco efficiente e gli si preferiscono le tecniche del free-behind (che rimuove una pagina dal buffer non appena si richiede la successiva) e la read-ahead (che carica in cache la pagina richiesta e parecchie altre tra quelle successive).
Infine, menzioniamo le RAM-disc o dischi virtuali che vengono gestite come normali file system dall'utente ma risiedono completamente in memoria centrale. Il loro vantaggio è l'indubbia velocità, che si paga con la volatilità dei dati.
Abbiamo visto che parte delle informazioni delle directory sono memorizzate in cache o memoria centrale per accelerarne l'accesso, dunque queste sono in media più aggiornate di quelle su disco. Cosa accadrebbe se un crash del sistema provocasse la perdita della RAM? Si perderebbe la coerenza tra le informazioni nei diversi supporti, con risultati spesso gravi.
Il controllore della coerenza ha il compito fondamentale di confrontare i dati nelle strutture delle directory e i blocchi di dati su disco: se non corrispondono cerca di ripristinare la situazione in uno stato coerente con delle tecniche che differiscono a seconda del tipo di allocazione adottata dal sistema.
Poiché i dischi sono soggetti a possibili guasti e contengono una notevole quantità di informazioni, si dovrebbero effettuare periodicamente dei salvataggi di sicurezza (backup) dei dati su altri dispositivi di memorizzazione, così che in caso di necessità possano essere ripristinati.
Per evitare di ricopiare ogni volta anche quei file o cartelle che nel frattempo non sono stati modificati, è possibile consultare prima i descrittori delle directory quindi salvare solo i file effettivamente cambiati.
I backup possono essere completi o incrementali. E' cosa saggia effettuare a scadenze regolari dei backup completi e custodirli con cura nel caso in cui un utente abbia bisogno di un file molto tempo dopo che si è guastato.