Torna alla pagina di Tecnologie Web
:: Appello d'esame di Tecnologie Web - 14/01/2009 ::
Esercizio 1
Considerando il seguente documento XML:
<?xml version="1.0" encoding="utf-8"?>
<xs:schema targetNamespace="http://bpms.intalio.com/FirstProcess/Time"
xmlns:ns="http://bpms.intalio.com/FirstProcess/Time"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
elementFormDefault="qualified">
<xs:element name="TimeRequest">
<xs:complexType>
<xs:sequence>
<xs:element name="city" type="xs:string"/>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name="TimeResponse">
<xs:complexType>
<xs:sequence>
<xs:element name="UTCTime" type="xs:string"/>
<xs:element name="cityTime" type="xs:string"/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>
1a. Definite il tipo di documento.
SOLUZIONE
E' uno schema XML. Gli schemi XML sono un miglioramento dei DTD con lo scopo quindi di definire la struttura di un documento XML e i tipi di dati. Uno schema definisce:
- gli elementi che possono apparire in un documento
- gli attributi che possono apparire in un documento
- le relazioni tra elementi padre-figlio
- l'ordine degli elementi
- il numero degli elementi
1.b Descrivete in linguaggio naturale il significato di quanto espresso nel documento.
SOLUZIONE
Questo schema è per un document XML che restituisce l'ora esatta andandola a prendere da un sito (http://bpms.intalio.com/FirstProcess/Time) e visualizzando a video il risultato.
Esercizio 2
Considerate la seguente istanza XML e le espressioni Xpath sottostanti:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="myfile.xsl" ?>
<bookstore specialty="novel">
<book style="textbook">
<author>
<first-name>Mary</first-name>
<last-name>Bob</last-name>
<publication>Selected Short Stories of
<first-name>Mary</first-name>
<last-name>Bob</last-name>
</publication>
</author>
<editor>
<first-name>Britney</first-name>
<last-name>Bob</last-name>
</editor>
<price>55</price>
</book>
<magazine style="glossy" frequency="monthly">
<price>2.50</price>
<subscription price="24" per="year"/>
</magazine>
<book style="novel" id="myfave">
<author>
<first-name>Toni</first-name>
<last-name>Bob</last-name>
<degree from="Trenton U">B.A.</degree>
<degree from="Harvard">Ph.D.</degree>
<award>Pulitzer</award>
<publication>Still in Trenton</publication>
<publication>Trenton Forever</publication>
</author>
<price intl="Canada" exchange="0.7">6.50</price>
<excerpt>
<p>It was a dark and stormy night.</p>
<p>But then all nights in Trenton seem dark and
stormy to someone who has gone through what
<emph>I</emph> have.</p>
<definition-list>
<term>Trenton</term>
<definition>misery</definition>
</definition-list>
</excerpt>
</book>
</bookstore>
Xpath1: book[/bookstore/@specialty=@style]
Xpath2: book/*/last-name
Xpath3: @*
Xpath4: my:book
Xpath5: book/author[last()]
Xpath6: author[* = "Bob"]
2a. Listate per ogni espressione Xpath i nodi XML ritornati.
NOTA: vedi esame 15/07/2008 per soluzione più precisa e completa.
1- Restituisce il secondo libro perché è l'unico con l'attributo style uguale all'attributo specialty(entrambi valgono "novel")
book[2]
2- restituisce gli elementi figli di book col nome "last-name", in questo caso entrambi valgono Bob, quindi preso dai due last-name dell'elemento "author", non dell'elemento "publication"
3- corrisponde a tutti i nodi degli attributi, quindi restituisce tutti gli attributi presenti nel documento
4- mmm non so perché l'ho messo
5- restituisce l'ultimo elemento figlio che fa parte dell'elemento "author", quindi in questo caso "publication"
6- restituisce l'elemento figlio "last-name" di author
2b. Scrivete un tipo di espressione Xpath non proposta nellesercizio.
SOLUZIONE
- bookstore/book/node()
- bookstore/magazine/@style
- bookstore/book/author/award
Esercizio 3
3a. Spiegate la differenza tra i due più diffusi parser XML: SAX e DOM.
SOLUZIONE
DOM (Document Object Model): definisce interfacce, proprietà e metodi per manipolare documenti XML.
SAX (Simple API for XML): è uninterfaccia per leggere e manipolare file XML (quindi è un'API basata su eventi per il parsing di documenti XML).
Differenze:
- modalità di interazione tra le API(Application Programming Interface) e lapplicazione che ne fa uso.
In DOM è indispensabile leggere e sottoporre a parsing tutto il documento prima che il relativo modello a oggetti possa essere messo a disposizione di un'applicazione DOM. Ciò comporta che l'intero documento venga mantenuto in memoria e questo provoca un overhead non indifferente. Questo aspetto rende DOM poco adatto per applicazioni di trasformazione di documenti o per applicazioni che richiedano il parsing incrementale dei dati, come i protocolli di comunicazione e scambio di messaggi. DOM infatti non fornisce alcun supporto esplicito per effettuare il parsing di documenti o la serializzazione di nuovi documenti verso dispositivi di memorizzazione esterni.
In SAX ogni volta che il parser incontra un tag iniziale, un tag finale, dei dati di tipo carattere oppure un'istruzione di elaborazione, lo comunica direttamente al programma client, di conseguenza non bisogna aspettare che l'intero documento venga letto prima di poter agire sui dati presenti all'inizio del documento, perché il documento stesso viene passato al programma pezzo per pezzo, dall'inizio alla fine. Quindi non è necessario che l'intero documento risieda in memoria (cosa che invece avviene con DOM).
Questo comporta - memoria, - tempo di caricamento, + tempo per singolo accesso.
3b. Spiegate brevemente i problemi legati alla codifica dei caratteri dei formati di testo.
SOLUZIONE
La globalizzazione di Internet ha proposto il problema di rendere correttamente gli alfabeti di migliaia di lingue nel mondo.
Il problema si pone per i dati scambiati dai protocolli, in quanto deve essere non ambiguo il criterio di associazione di un blocco di bit ad un carattere di un alfabeto.
Come trasmettere un messaggio con uno strumento in grado di trasmettere solo punti e linee? Ovviamente è necessaria una codifica: ad ogni carattere associamo un numero che trasmettiamo o, nel nostro caso, memorizziamo.
Una codifica che si affermò in modo universale fu quella standard ASCII (1963), che comprendeva 128 caratteri (7 bits) tra cui alcuni caratteri di controllo che erano utilizzati per le trasmissioni e la gestione del terminale. 128 caratteri non sono molti ma erano sufficienti per codificare la lingua inglese che non usa le lettere accentate.
Per permettere la codifica di lingue che utilizzano molti caratteri accentati lo standard ASCII fu esteso a 8 bits.
Per semplificare le comunicazioni nell'era dell'informatizzazione globale è stata introdotta una codifica detta UNICODE in cui si arrivano ad utilizzare fino a 32 bits per carattere: è possibile rappresentare anche tutti gli ideogrammi cinesi.
Esercizio 4
CGI: cosa sono, come funzionano, problemi.
SOLUZIONE
CGI (Common Gateway Interface) è uninterfaccia standard che permette ad un web server di comunicare con altre applicazioni e programmi autonomi.
Funzionamento:
- Il client esegue una richiesta al web server.
- Il web server passa la richiesta ad un programma esterno.
- Il programma esterno riceve la richiesta, crea contenuti dinamici che tramite il server vengono inviati al client.
Problemi:
- Vengono mischiate presentazione e logica: formato scomodo sia per gli sviluppatori che per i programmatori.
- Velocità: ad ogni richiesta del client, il server deve inoltrare questa richiesta al programma CGI che nel frattempo era stato chiuso (CGI stateless).
- Ad ogni richiesta di risorsa alla CGI, il web server crea un nuovo processo à spreco di risorse.
Esercizio 5
Cookies: cosa sono, vantaggi e svantaggi.
SOLUZIONE
I Cookie sono dei file di testo non interpretabili lasciati in consegna ad un client che può grazie ad essi mantenere lo stato di precedenti connessioni.
Alla prima richiesta di un client, il server fornisce la risposta più un header aggiuntivo, il cookie, con dati arbitrari, e con la specifica di usarlo per ogni successiva richiesta.
Prima di effettuare ogni richiesta al server, il client verifica se ha sul suo disco un cookie di quel server; se lo trova ne copia il contenuto nell'header della richiesta HTTP.
In sostanza i cookie permettono di simulare una sessione.
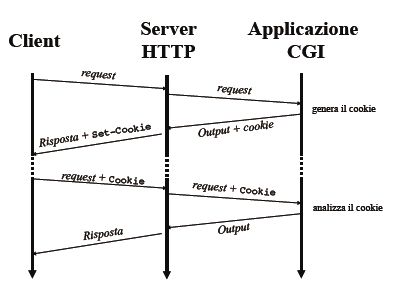
Esempi di campi contenuti in un cookie:
Comment: una stringa leggibile di descrizione del cookie.
Domain: il dominio per cui il cookie è valido.
Max-Age: la durata di validità del cookie in secondi.
Path: l'URI per il quale il cookie è valido.
Secure: la richiesta che il client contatti il server usando soltanto un meccanismo sicuro(HTTPS).
Version: la versione della specifica a cui il cookie aderisce.
Lo svantaggio dei cookie è che possono portare ad una violazione della privacy e, nel caso si riuscisse a leggere i cookie di un determinato utente, provocare spamming.
Nota: i cookie essendo file di testo non possono essere portatori di virus, perché non possono essere eseguiti, cosa necessaria per qualsiasi codice dannoso.
Esercizio 6
Scrivere un esempio di codice JSP in cui viene dichiarato e inizializzato un array di stringhe (String) di dimensione fissata. Il codice deve poi stampare a video il contenuto dellarray, specificando la posizione della stringa nellarray e il contenuto. Spiegare quali elementi di script sono stati utilizzati.
<html>
<head>
<title> Esercizio 6 <\title>
<\head>
<body>
<%-- dichiarazione e inizializzazione dellarray--%>
<%-- stampa--%>
<\body>
<\html>
SOLUZIONE
<html>
<head>
<title> Stringhe </title>
</head>
<body>
<%
String [] strings=new String[3];
strings[0]= gli;
strings[1]= amici;
strings[2]= swappa;
for (int i=0; i<strings.length; i++) { %>
String[<%= i %>] = <%=strings[i] %> <br>
<% } %>
</body>
</html>
Torna alla pagina di Tecnologie Web