Torna alla pagina di Ingegneria del Software
:: Ingegneria del Software - Appunti del 20 Aprile 2009 ::
UML e il mondo reale
Come più volte affermato (ma mai visto in diretta) UML ha anche una bella semantica. Come abbiamo visto in lezioni precedenti, avere una semantica è una bella cosa.
Tuttavia, nel mondo reale spesso si tende ad utilizzare UML in modo meno formale rispetto alle sue potenzialità. Infatti, se viene usato in fase di analisi, cioè quando si parla col cliente, e quando si danno le istruzioni al programmatore, spesso si tralascia la semantica e si preferisce parlarne: in questo caso la semantica diventa la comprensione condivisa, che non garantirà di avere una visione oggettiva e benché meno sarà traducibile in linguaggio matematico.
La semantica di UML si chiama MOF = Meta Object Format. e ci permette di verificare se il nostro modello ha certe proprietà. I tool UML che si usano integrano spesso un'implementazione del MOF, e la usano continuamente per controllare i diagrammi che facciamo (perlomeno, per avvisarci di possibili incongruenze nel nostro modello, ad esempio la comparsa di una classe nel diagramma delle sequenze che non appare nel diagramma delle classi). Tanto per citare un software che dispone di questo tool, Argo consente di fare questo tipi di controlli sul diagramma UML che si sta costruendo.
Inoltre il MOF permette di avvicinarsi all'idea del Graal dei software engineer: un software che si scrive da solo dato un modello:)
Gli stereotipi
Gli stereotipi sono delle categorie precostituite cui far appartenere le classi. In un certo contesto applicativo, ad esempio, si nota che le classi che abbiamo inventato si dividono in tre ruoli distinti: Mangiare, Bere e Dormire. Ecco quindi uno stereotipo, cioè una suddivisione delle classi in categoria pronta all'uso anche in un altro progetto, un po' come i pattern.
La differenza tra un pattern e uno stereotipo è che il pattern rappresenta un embrione di soluzione di design, mentre lo stereotipo è solamente un'etichetta che si appiccica alle classi per poterle raggruppare (e in certa misura quest'etichetta verrà sfruttata quando si cercherà di dividere il nostro software in componenti separate e ben coese).
Ecco due divisioni in stereotipi:
- Business, Service, Interface: qui distinguo le classi in base al loro dominio applicativo
- Contorno, Controllo, Entità, Utilità, Eccezione
- Contorno = vengono chiamate ma non chiamano mai
- Controllo = il tramite tra le classi
- Entità = classi di business, cioè entità del dominio applicativo di cui facciamo un modello
- Utilità e Eccezione si spiegano da sé
La fattorizzazione
Fino ad ora, il nostro percorso verso il software è stato il seguente:
- analisi dei requisiti
- casi d'uso
- diagrammi vari e delle classi
- sw
Tutto ciò viene sentito da diverse persone come macchinoso e troppo lungo, e spesso si preferisce passare direttamente dai requisiti alle classi. Un metodo che si usa in questo frangente è proprio la fattorizzazione. Viene anche chiamata Object Oriented Analysis.
I requisiti
I requisiti saranno della forma a noi cara soggetto - verbo - oggetto. A noi interessano i requisiti funzionali, cioè quelli che specificano una funzione che il sistema deve compiere.
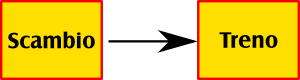
Per esempio, nei requisiti di uno scambio ferroviario potremo trovare le seguenti frasi:
- lo scambio riceve il treno sulla linea x
- lo scambio inoltra il treno sulla linea y
in cui oltre all'oggetto c'è anche un ulteriore complemento, ma questo non è un problema perché la struttura di base sogg-verbo-ogg è rispettata.
Per fattorizzare, si devono prendere tutti i requisiti che hanno lo stesso soggetto. In questo caso, ho due requisiti, e il soggetto di entrambi è lo scambio. Bene: il soggetto isolato diviene una classe.
Il passo successivo è prendere tutti i verbi che compaiono nei requisiti del nostro soggetto testé isolato. Qui i verbi sono riceve e inoltra: i verbi diverranno le responsabilità della nostra classe Scambio (vediamo poi che cosa sono).
Infine, tutti gli oggetti dei nostri requisiti isolati diventeranno collaborazioni all'interno della nostra classe.
Ricapitolando, isolo tutti i requisiti con lo stesso soggetto. Di questi requisiti:
- Il soggetto diviene una classe
- I verbi divengono responsabilità
- Gli oggetti divengono '''collaborazioni
CRC Cards

Una prima CRC Card dello scambioFatto questo, inseriamo il tutto in una CRC card.
CRC sta per Class-Responsibility-Collaborator. Si tratta di un sistema di fattorizzazione inventato da Kent Beck e Ward Cunningham nel lontano 1989.
Nel nostro esempio, quello dello scambio ferroviario, dal momento che ho nelle collaborazioni sia treno che linea, emerge la necessità di avere altre classi, proprio per rappresentare il treno e la linea. Le collaborazioni sono infatti relazioni tra classi, e se qualcosa compare nella sezione collaborazioni deve per forza avere una sua dignità come classe.
Classificare le collaborazioni
Le relazioni tra classi sono quelle viste nella lezione precedente. All'inizio le rappresenteremo come linee tratteggiate, e poi penseremo a quale tipo di relazione tra classe (ereditarietà, aggregazione, composizione) esse rappresentano.
Più sotto si svilupperà meglio questo concetto.
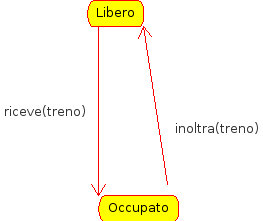
Attributi di stato
Nella card vista sopra mancano alcune cose importanti, ovvero gli attributi di stato. Un attributo di stato è un attributo il cui valore determina un output diverso dai metodi. Se pensiamo al funzionamento interno di una classe come ad una macchina a stati, ovvero un Automa, allora sappiamo che lo stesso metodo mi darà risultati diversi a seconda dello stato in cui si trova la macchina in quel momento.
Prendiamo lo scambio: se lo stato è libero, la richiesta del treno riceve() sarà soddisfatta. Se invece lo stato è occupato, la richiesta del treno non potrà essere soddisfatta.
Per convenzione se una classe ha un attributo di stato vengono aggiunti i metodi check() e set() per controllare e variare il suo valore.
Come facciamo ad identificare gli attributi di stato? La domanda cui rispondere è questa: c'è qualcosa che la classe deve sapere affinché possa dare il risultato opportuno?.
Diagrammi stati-transizioni
Tutte le volte che una classe presenta attributi di stato, è mandatorio realizzare il relativo diagramma stato-transizione, ovvero l'automa. Anche i tool UML mi "obbligheranno" a farlo, e soprattutto ci obbligherà a farlo il professore per presentare il progetto d'esame.
Ma attenzione: questo diagramma va fatto classe per classe. Non è opportuno fare un automazzo immenso che tiene conto di tutto il software, altrimenti si diventa folli. Si prendono invece tutte le classi che hanno degli stati, e di queste si fa il diagramma stati-transizioni.
Le variazioni di stato in una classe sono governate da chiamate ai metodi che ne mutano gli attributi di stato. In un diagramma di stato, pertanto, passerò da uno stato all'altro con transizione scatenate appunto da chiamate a questi metodi.
In UML è anche possibile specificare, per ogni attributo di stato, un valore di default, cioè il valore che quello stato avrà di default nel momento in cui viene istanziato un oggetto appartenente a quella classe.
In linea teorica, per ogni variazione di un attributo di stato, deve esserci una freccia che esce da uno stato e porta ad un altro. In pratica, questo lo si può evitare nella maggior parte dei casi: prendiamo ad esempio un buffer che può contenere 10 elementi. Potrei avere un attributo di stato che mi dice quanti elementi contiene il buffer: 0 = vuoto, 1, 2, ... 10 = pieno, per un totale di 10 diversi valori. In realtà quello che mi serve è avere un attributo con solo 3 valori logici: vuoto, spazio disponibile e pieno. Posso poi esprimere questi stati logici in condizioni numeriche, ad esempio Elementi = 0, Elementi < 10, Elementi = 10, e metterle come condizioni alle mie transizioni.
Se invece scelgo di rappresentare il tutto con una tabella, allora metto tutte le combinazioni tra stati nella tabella, e via.
È anche possibile fare prima il diagramma di stato, e poi inventarsi gli attributi di stato che servono per implementarlo. Questo viene utile quando si ha in mente una sequenza di avvenimenti, e si preferisce prima scriverla giù, e poi fare in modo di "ridurla" ad un certo numero di stati.
Relazioni tra classi
Come facciamo a stabilire quale tipo di relazione associare ad una linea tratteggiata, oltre che a litigare con i colleghi? Esiste una tecnica chiamata test del ciclo di vita, che dice che se due oggetti nascono e muoiono insieme, si tratta di composizione. Se invece nascono e muoiono in tempi diversi, allora è aggregazione. Se invece i loro rapporti sono occasionali, allora è associazione (ad esempio auto-pilota).
Nel nostro esempio, possiamo intuire che lo Scambio e la Linea siano legati da una bella composizione, poiché non ci è dato immaginare uno Scambio senza una Linea. Invece, tra Treno e Scambio ci sarà un'associazione, ma nulla di più: il treno sa giusto che deve passare per uno scambio, ma non gliene importa più di tanto, e viceversa.
Navigabilità
La navigabilità di un'associazione viene rappresentata dal verso di una freccia. La presenza di una freccia non indica asimmetria della relazione, ma mi dice che - a livello di codice (C++, Java etc.) - da Scambio sarò in grado di raggiungere Treno, ovvero che un'istanza della classe Scambio avrà un attributo che mi permette di raggiungere un'istanza della classe Treno.
Come dicevamo sopra, non sempre lo Scambio avrà nozione di un Treno in arrivo o in partenza, tuttavia, quando ciò si rende necessario, lo Scambio dovrà sapere quale treno è in arrivo o in partenza.
Le frecce dunque indicano il senso di percorrenza che viene utilizzato in fase di codifica, dove le relazioni tra classi sono espresse tramite attributi di relazione, e la navigabilità mi indica quale delle due classi coinvolte lo contiene. Nel caso in cui non ci fossero frecce allora entrambe le classi devono avere tale attributo.
Questa faccenda delle frecce e della loro navigabilità è di capitale importanza nella fase di implementazione del codice, perché a seconda del tipo di freccia dovrò scrivere codice in modo diverso, ma non solo: ogni linguaggio di programmazione mi costringerà ad utilizzare certi costrutti per realizzare un certo tipo di associazione, mentre un altro linguaggio di programmazione mi costringerà ad utilizzarne altri. La faccenda non è per niente da sottovalutare, perché oltre a richiedere la comprensione del problema (il che si traduce nel dover tracciare il diagramma corretto), serve anche una comprensione del linguaggio di programmazione che viene utilizzato.
Bisogna quindi stare attenti: in UML gli attributi di relazione rimangono impliciti, e prenderanno vita solamente durante l'implementazione, poiché sono language-dependent, cioè dipendono dal linguaggio di programmazione scelto.
Diagramma delle classi e di sequenza
Entrambi i diagrammi presentano, come oggetti, delle classi. C'è una cosa di cui tenere conto: nel diagramma di sequenza non deve essere possibile avere una classe che non appaia anche nel diagramma delle classi. La ragione di ciò è abbastanza ovvia.
Tuttavia, la situazione speculare è invece ammessa, cioè è possibile avere nel diagramma delle classi una classe che poi non compaia nel diagramma di sequenza. È ammessa, e il tool UML non ci dà errore, perché può trattarsi di una classe astratta, cioè una classe destinata a non avere istanze, ma a generare figli.
Il tool, in questo caso, non ci darà errore, come invece ce lo darà nell'altro caso. Ma non ci dà errore solo perché non è in grado di controllare se la classe è astratta o non astratta, e nel dubbio si astiene. Spetta al designer verificare la coerenza tra i diagrammi in una simile evenienza.
Il diagramma di sequenza si rende necessario, dopo aver disegnato il diagramma delle classi, per rappresentare - almeno in linea teorica - tutti i requisiti funzionali. Infatti il diagramma di sequenza ci spiega come le varie classi si parlano al fine di arrivare all'obiettivo del requisito.
Riprendiamo poi due consigli/regole già visti nella lezione precedente:
- tutti gli attributi di stato di una classe vanno resi accessibili (sia in lettura che in scrittura) SOLO tramite metodi check e set, così che variazioni di tali attributi possano essere controllabili e VISIBILI nel diagramma di sequenza
- tutte le linee di comunicazione tra due classi, nel diagramma di sequenza, DEVONO avere nomi di metodi
Per poter tracciare una freccia nel diagramma di sequenza, è quindi necessario che la classe chiamata presenti nella propria interfaccia un metodo con quel nome.
Infine, ricordiamo che se si traccia il diagramma delle sequenze, non si fa il diagramma di collaborazione, visto che si tratta praticamente della stessa cosa presentata sotto due pdv leggermente diversi.
Reti di Petri e generazione automatica del codice
Come abbiamo visto precedentemente, le Reti di Petri servono per ovviare ad alcuni problemi degli Automi. Sono state aggiunte ad UML solo di recente (nella versione 2.0), e il motivo è che se è presente una Rete di Petri, un tool potrebbe essere in grado di generare il codice corretto in modo automatico.
Infatti, dato un diagramma, un tool è in grado di scrivere l'interfaccia della classe e magari i metodi check e set degli attributi. Tuttavia, il contenuto dei metodi va comunque scritto a mano. Se invece è presente un automa o, meglio, una Rete di Petri, allora il tool può generare automaticamente anche il codice interno al metodo.
CRC Cards: la versione completa
Le CRC cards viste prima sona un po' semplici, per i nostri scopi. In realtà sono un po' più complesse.
| Nome della Classe
|
| Responsabilità principale della classe
|
| Responsabilità:
| Collaborazioni:
|
| Resp. 1
| Collab. 1
|
| Resp. 2
| Collab. 2
|
| Resp. 3
| Collab. 3
|
Dal punto di vista pratico, accade che in un'azienda ci si sieda attorno ad un tavolo a fare brainstorming, e poi si compilano manualmente certe schede di carta, che sono proprio le CRC Cards. Si litiga sui seguenti punti:
- dare il nome alle classi
- scegliere le responsabilità, che diventeranno metodi
- ripartire le responsabilità tra le diverse classi
- non duplicare le responsabilità
- regola verso l'alto: se ci sono tante classi con responsabilità in comune, si può provare a vedere se hanno un genitore comune
Anche nel progetto che dovremo consegnare dovremo stare attenti a questi punti, perché una buona valutazione dipende anche da ciò.
XP: Xtreme Programming
L'Xtreme Programming è una tecnica tramite la quale si passa dalle CRC cards al codice senza passare per il resto dei diagrammi UML.
In generale si usa UML perché (se usato bene) produce documenti che obbligano i programmatori a scrivere codice che non sgarri, e conseguentemente la manutenzione (che rappresenta l'80% del costo di un sw) sarà molto facilitata.
Ma quelli che hanno inventato XP si sono resi conti che è possibile garantire la leggibilità del codice senza passare da UML, ma tramite il co-sviluppo: due persone contemporaneamente lavorano allo stesso codice, e si alternano alla tastiera ogni 1/2 ora. Uno scrive, l'altro guarda e lo interroga, e viceversa: in questo modo si controllano a vicenda, e si può garantire un bel codice pulito e rispettoso delle scelte di design. In inglese questa roba si chiama pair programming, e ci sono aziende in cui ogni mezz'ora suona una campanella e i programmatori sono tenuti a scambiarsi di posto.
Se il codice è scritto bene, allora si autodocumenta: in pratica il codice è il diagramma UML di se stesso.
DOMANDA D'ESAME
È possibile che UML non venga fatto all'interno del processo di sviluppo di un'azienda?
Risposta: Sì, con il Pair Programming, il quale garantisce comunque la leggibilità del codice.
Ultima considerazione sulle classi
Dal momento che le classi UML hanno una granularità piuttosto piccola, difficilmente saranno utilizzate come unità (formato) di consegna del software. Ad esse si preferiscono invece le componenti, che contengono più classi e che affronteremo meglio nelle prossime lezioni.
Torna alla pagina di Ingegneria del Software