Torna alla pagina di Informatica Teorica
:: Informatica Teorica - Automi a pila ::
Appunti & Dimostrazioni del 14 Aprile
Nel capitolo precedente abbiamo imparato che una CFG è in grado di costruire un linguaggio libero dal contesto (da ora, anche CFL). Ora introduciamo un nuovo tipo di modello computazionale che si occupa di riconoscere i linguaggi, ovvero l' automa a pila (PDA, Push-Down Automata).
L'automa a pila è molto simile agli automi non deterministici, ma ha un optional che tutti gli NFA gli invidiano: lo stack, che fornisce memoria aggiuntiva al PDA, permettendogli di riconoscere anche i linguaggi non regolari.
Dato che l'automa a pila ha la stessa potenza descrittiva di una CFG, potremo usarlo per dimostrare che un certo linguaggio è libero dal contesto. E' un'equivalenza importante, perché alcuni linguaggi sono più semplici da descrivere in termini di riconoscimento che di generazione.
Ecco un confronto tra gli schemi di un NFA e un PDA:
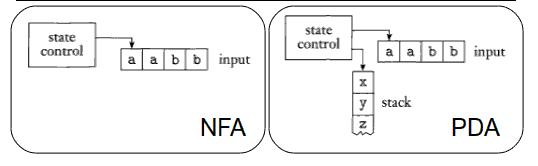
Lo state control rappresenta gli stati e le funzioni di transizione, il nastro rappresenta le stringhe in ingresso, mentre le frecce rappresentano la testina dell'ingresso, che punta al prossimo simbolo che deve essere letto. Nel PDA fa la sua bella comparsa anche lo stack, su cui il PDA può scrivere e leggere simboli in modalità "last in, first out". La scrittura sullo stack è chiamata pushing, e consiste nell'inserimento di un nuovo simbolo nella posizione in cima alla pila, spingendo giù tutti gli altri di una posizione; la lettura invece è detta popping e consiste nell'estrazione del simbolo in prima posizione, che viene appunto letto e rimosso. Si noti che lo stack può contenere una quantità illimitata di informazioni, quindi ad esempio sarà in grado di riconoscere un linguaggio non regolare come: {0n1n|n>=0}. Come? Basterà leggere un simbolo da input e pushare ogni 0 letto nello stack (che è illimitato); quando poi arriveremo agli 1, farà il popping di uno 0 per ogni 1 letto, e se alla fine dei giochi lo stack è vuoto allora l'ingresso sarà accettato.
Concludiamo la panoramica iniziale sottolineando che l'automa a pila può essere sia deterministico che n.d., che non sono equivalenti in termini di potenza: il PDA n.d. riconosce molti più linguaggi dell'altro.
La definizione formale di automa a pila è molto simile a quella dell'automa a stati finiti, con l'unica eccezione della presenza dello stack, che può avere un alfabeto diverso rispetto a quello d'ingresso.
Un automa a pila è una 6-upla (Q,Σ,Γ,δ,q0,F), dove:
Siano dati:
Diciamo allora che M accetta w se esiste una sequenza di stati r0r1..rm in Q che rispettino tre condizioni:
Dare la definizione formale del PDA che riconosce il linguaggio {0n1n|n>=0}.
Soluzione
Qualche riga fa avevamo fatto una descrizione alla buona di come avrebbe dovuto comportarsi un automa a pila per riconoscere il linguaggio. Cerchiamo ora di dare una spiegazione più seria.
La lettura dei simboli in ingresso da parte del PDA può essere distinta in due fasi:
Se la lettura della stringa in ingresso finisce in concomitanza con lo svuotamento completo dello stack, allora la stringa è accettata; altrimenti è rifiutata.
Cominciamo ora con le definizioni formali.
Sia dato un automa a pila M=(Q,Σ,Γ,δ,q1,F), dove:
| Input: | 0 | 1 | ε | ||||||
| Stack: | 0 | $ | ε | 0 | $ | ε | 0 | $ | ε |
| q1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | {(q2,$)}
|
| q2 | 0 | 0 | {(q2,0)}
| {(q3,ε)}
| 0 | 0 | 0 | 0 | 0 |
| q3 | 0 | 0 | 0 | {(q3,ε)}
| 0 | 0 | 0 | {(q4,ε)}
| 0 |
| q4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
Il comportamento di questo PDA si capisce meglio rappresentandolo con un più familiare diagramma degli stati:
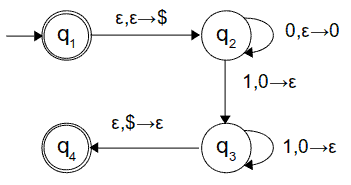
Come interpretare le frecce? Ad esempio, a,b -> c va letto come: quando l'automa legge il simbolo a dall'ingresso, dovrà sostituire il simbolo b che si trova in cima allo stack con il simbolo c. In pratica b si riferisce a un pop e c a un push.
Riferendoci al diagramma degli stati, vediamo come si comporta l'automa:
A inizio capitolo abbiamo detto che l'automa a pila ha la stessa potenza descrittiva di un CFG. Non l'avessimo mai fatto: ora ci tocca dimostrarlo.
Un linguaggio è libero dal contesto se e solo se esiste un automa a pila che lo riconosce.
Dimostrazione
Il teorema è un "se e solo se", quindi vanno dimostrati entrambi i sensi delle implicazioni.
(I) Se un linguaggio è libero dal contesto, allora esiste un PDA che lo riconosce
Dato che per definizione un CFL è generato da una grammatica libera dal contesto, non dobbiamo fare altro che dimostrare che ogni CFG G può essere convertita in un equivalente PDA P. In pratica dobbiamo costruire P in modo che se gli passiamo in ingresso una stringa w generata da G, questi dovrà accettarla. Ma come fa a capire se è davvero generata dalla grammatica a lui equivalente? Dovrà verificare (in modo n.d. se tra tutte le derivazioni possibili della grammatica ne esiste una che dalla variabile iniziale porta a w.
Più nel dettaglio, P comincia la sua computazione scrivendo la variabile iniziale sullo stack; poi prosegue attraverso una serie di stringhe intermedie ottenute sostituendo le variabili secondo le regole della grammatica; infine quando arriva a una stringa composta da soli terminali la confronta con w: se corrispondono allora P accetta, altrimenti abbandona quel ramo della computazione.
Tutto ciò è molto bello, ma dove le memorizzo le stringhe intermedie? Anche se la tentazione è forte, non posso metterle così come sono nello stack. Se infatti dovessi fare una sostituzione di una variabile in una stringa intermedia e questa non si trova in cima allo stack, dove pensate che la prenderemo? Esatto, proprio là dietro. La soluzione è conservare solo una parte della stringa intermedia nello stack, quella che va dalla prima variabile in poi; tutti i simboli che vengono prima devono corrispondere con la stringa in ingresso, altrimenti buttiamo via tutto.
Siamo pronti.
Sia dato l'automa a pila P=(Q,Σ,Γ,δ,q1,F). Per rendere la costruzione più chiara, descriveremo la funzione di transizione con la notazione breve, che permette di scrivere sullo stack una stringa intera con un unico passo della macchina (normalmente invece per scriverci su una stringa di dieci caratteri, ad esempio ACCABANANA, dovremmo fare 10 passi).
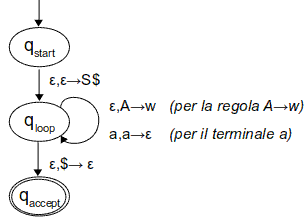
I tre stati fondamentali di P sono Q={qstart, qloop, qaccept}, in cui qstart è quello iniziale e qaccept l'unico accettato. Diamo ora una descrizione del funzionamento di P:
{(qloop,S$)}{(qloop,w) | dove A->w è una regola in R}{(qloop,ε)}{(qaccept,ε)}Ed ecco finalmente il diagramma degli stati di P in tutta la sua fierezza:
(II) Se un PDA riconosce un linguaggio, allora è un linguaggio libero dal contesto
Situazione inversa: abbiamo un PDA P e vogliamo creare un CFG G che generi tutte le stringhe accettate da P. Seguitemi prima con la costruzione, poi verificheremo se ci aiuta a dimostrare l'implicazione (tenetevi pronti: ci sarà un altro "se e solo se" da affrontare).
Come prima cosa, dovremo aggiungere alla nostra grammatica G una variabile Apq per ogni coppia di stati p e q in P. Non è una variabile a caso, ma quella che genera tutte le stringhe che possono portare il PDA da p a q lasciando lo stack nelle stesse condizioni in cui lo si è trovato (o vuoto o con lo stesso contenuto). Per riuscirci, dobbiamo fornire a P tre nuove caratteristiche:
Qualcosa sul comportamento di P già si capisce da queste caratteristiche: la prima operazione su una qualsiasi stringa x sarà di push, e l'ultima di pop. E le altre? Distinguiamo due casi:
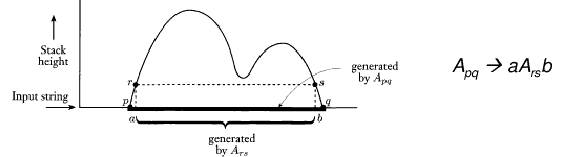
La costruzione di G termina aggiungendo per ogni p ∈ Q la regola: App->ε.
La costruzione è questa, ma per dimostrare la seconda implicazione del Teorema 1 (ve lo ricordate ancora?) dovremo dimostrare che Apq genera una stringa x se e solo se x può portare P da p con stack vuoto a q con stack vuoto. Distinguiamo ancora i due versi dell'implicazione.
(II.a) Se Apq genera x, allora x può portare P da p con stack vuoto a q con stack vuoto
La dimostrazione viene fatta per induzione.
(II.b) Se x può portare P da p con stack vuoto a q con stack vuoto, allora Apq genera x''
Anche in questo caso la dimostrazione va fatta per induzione.
Quindi, ricapitoliamo. Dovevamo dimostrare questo teorema:
Un linguaggio è libero dal contesto se e solo se esiste un automa a pila che lo riconosce.
Avendo dimostrato tutti i possibili "se e solo se" nei casi (I), (II.a) e (II.b), possiamo finalmente dire che 'sto teorema immondo è dimostrato!
Ebbene sì, quell'incubo aveva anche un corollario:
Ogni linguaggio regolare è libero dal contesto.
Esticazzi.