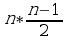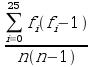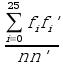:: Crittografia - Lezione del 12 Marzo 2008 ::
Torna alla pagina di Crittografia
Crittanalisi
Dopo aver visto come crittare le cose in diversi metodi, vediamo un po' i sistemi per decrittare.
La regola di Kerckhoffs, che abbiamo già visto, dice che la sicurezza di un crittosistema deve dipendere solo dalla segretezza della chiave e non dalla segretezza dell'algoritmo usato.
In effetti, tutte le tecniche moderne di crittografia vengono rese pubbliche, così che si possa testarne la robustezza permettendo a chiunque di romperle.
Ci sono diverse situazioni di attacco, che corrispondono a diversi gradi di sicurezza. Più un crittosistema resiste a livelli di attacco più alti, più è robusto.
- known ciphertext attack: l'attaccante conosce solo il testo cifrato
- known plaintext attack: si conosce il testo in chiaro, oltre a quello cifrato
- chosen plaintext attack: l'attaccante può ottenere la cifratura di un testo in chiaro a sua scelta
- chosen ciphertext attack: l'avversario può ottenere la decifratura di un testo cifrato a sua scelta
- chosen text attack: l'avversario ottiene cifratura e decifratura di coppie di testi in chiaro.
Se un cifrario viene rotto conoscendo solo il testo cifrato, allora è molto debole.
Se invece un attaccante riceve tutte le coppie di testo in chiaro e cifrato che vuole, e non sa come uscirne, allora vuol dire che il mio cifrario è molto robusto.
Crittanalisi di cifrari a shift
Questi cifrari sono quelli che prendono una lettera e la spostano di tot posizioni nell'alfabeto.
La struttura sottostante del testo però rimane, ed in particolare la frequenza delle lettere cifrate corrisponde alla frequenza delle lettere in chiaro nella lingua in cui è stato scritto il testo.
Le frequenze di un testo si ricavano facilmente, poi si vede quali frequenze corrispondono a quelle del testo cifrato.
Sostituzione monoalfabetica
Mappo le lettere qua e là finché non trovo la chiave. Computazionalmente parlando è molto semplice.
Cifrario di Hill
Era quello con le funzioni:
y^_1_^ = ax^_1_^ + bx^_2_^ mod 26
y^_2_^ = cx^_1_^ + dx^_2_^ mod 26
Questo cifrario può essere rotto conoscendo il testo in chiaro ed il testo cifrato: known plain text.
Se K è la chiave, M il testo in chiaro e C quello cifrato, ho le seguenti relazioni:
C = M * K
Ma ho anche:
M-1 * M * K = M-1 * C
=> 1 * K = M-1 * C
=> K = M^'-1'^ * C
dove M-1 è la matrice inversa di M. Se riesco a farmi un'idea delle dimensioni della matrice M, posso più o meno far saltar fuori la matrice inversa.
Cifrario di Vigenere
Abbiamo già visto che l'analisi delle frequenze non serve, con Vigenere.
Però, se riesco a capire quanto è lunga la chiave, riesco anche a capire quanti alfabeti cifranti sono stati utilizzati.
Il test di Kasiski cerca di determinare la lunghezza della chiave, con un po' di fortuna.
Faccio subito un esempio:
Testo in chiaro: Gattodiquagattodila
Chiave: DARIO
Testo cifrato: jakbcvugmfjakbcpieq
Si vede subito l'idea di Kasiski. Se sono fortunato, trovo delle sequenze ripetute di caratteri all'interno del testo cifrato. Potrebbe quindi voler dire che quelle sequenze ripetute sono la cifratura dello STESSO testo in chiaro cifrato con la STESSA parte della chiave.
La distanza fra le ripetizioni in questo caso è 5. Deduco che con buona probabilità la chiave sia di 5 caratteri.
Certo, occorre che le ripetizioni siano in effetti cifrature dello stesso testo.
Ma ciò non è improbabile. Ci sono molte parole che si ripetono, per esempio l'articolo determinativo il o the in inglese, e cose del genere. È probabile che le parole comuni vengano cifrate allo stesso modo in più parti del testo.
Generalizzando, quando trovo delle ripetizioni a distanze diverse, il Massimo Comun Divisore tra le varie distanze mi dà la lunghezza della chiave.
Friedman nel 1920 inventa un altro sistema per dedurre la lunghezza della chiave, l'indice di coincidenza.
In astratto, si mettono due testi uno sopra l'altro e si conta quante volte la stessa lettera compare nella stessa posizione in entrambi i testi, e si ricava la probabilità di avere due lettere uguali nella stessa posizione.
La probabilità dicevamo essere n / m, dove n sono i casi favorevoli, ed m i casi possibili.
I casi possibili sono dati dalla seguente formula:
dove n è la lunghezza del mio testo.
I casi favorevoli sono questi:
dove fi è la probabilità di pescare la i-esima lettera in quella posizione.
Le lettere sono 26, quindi devo fare la sommatoria delle 26 f^_i_^, per ricavare la seguente formula:
Ogni lingua ha il suo particolare indice di coincidenza. Per esempio, l'inglese ha 0.065. Un testo puramente casuale invece presenta un indice di coincidenza di 0.038.
Come applico sta roba a Vigenere?
Suddivido il mio testo cifrato in blocchi di una certa lunghezza, e li metto tutti in colonna, col primo blocco in alto e gli altri tutti sotto a seguire.
Calcolo poi l'indice di coincidenza delle colonne. Perché?
Il motivo è che se il mio blocco è lungo come la chiave, allora vuol dire che i caratteri nella stessa colonna sono stati cifrati con la stessa lettera. Pertanto, se l'indice di coincidenza della colonna assomiglia a quello della lingua del testo in chiaro, allora posso presumere che la chiave è lunga come il mio blocco.
Altrimenti, provo con un blocco via via più grande etc.
Questo vuole anche dire che ogni colonna è in pratica cifrata con Cesare: tutte le sue lettere hanno subito uno shift fisso. L'analisi delle frequenze, se il testo è abbastanza grande, può aiutarmi, in questo caso.
C'è infine l'indice mutuo di coincidenza. Dopo aver creato le mie colonne, le considero come delle stringhe a se stanti. Definisco quindi l'indice mutuo di coincidenza come la probabilità che due caratteri, uno preso da una stringa ed uno preso da un'altra, siano uguali.
L'indice mutuo di coincidenza tra due stringhe sarà quindi:
in cui fi è la frequenza della i-esima lettera nella prima stringa, e fi' è la frequenza della i-esima lettera nella seconda stringa.
Abbiamo parlato di caratteri uguali. Ma sappiamo che ogni colonna, ovvero ogni nostra stringa in questo calcolo, è stata ottenuta applicando ai caratteri di quella colonna del testo in chiaro uno shift fisso, al modo di Cesare.
Se entrambe le colonne fossero state shiftate con lo stesso valore, avremmo un indice mutuo di coincidenza pari a 0.075. Detto in altri termini, lo shift relativo tra le due colonne è 0, cioè la differenza tra lo shift della prima colonna e lo shift della seconda colonna è 0.
Se invece lo shift relativo fosse 1, avrei un indice mutuo di coincidenza di 0.033, etc. etc. Ogni lingua ha il suo shift relativo.
Quanti sono i possibili shift relativi? Dato che siamo in modulo 26, la distanza massima tra due lettere è 13.
Il procedimento è quindi quello di calcolare lo shift relativo tra la prima colonna e la seconda. Calcolato questo, posso calcolare quello tra la seconda e la terza e così via, poi tra la prima e la terza, la pima e la quarta etc. etc. etc. In questo modo ottengo un sistema lineare che si può risolvere facilmente, e ottengo la mia bella chiave.
Torna alla pagina di Crittografia